
PC Atomic Sync 1.7 serial key or number

PC Atomic Sync 1.7 serial key or number
CoffeeScript is a little language that compiles into JavaScript. Underneath that awkward Java-esque patina, JavaScript has always had a gorgeous heart. CoffeeScript is an attempt to expose the good parts of JavaScript in a simple way.
The golden rule of CoffeeScript is: “It’s just JavaScript.” The code compiles one-to-one into the equivalent JS, and there is no interpretation at runtime. You can use any existing JavaScript library seamlessly from CoffeeScript (and vice-versa). The compiled output is readable, pretty-printed, and tends to run as fast or faster than the equivalent handwritten JavaScript.
Latest Version:2.5.1
Overview
CoffeeScript on the topleft, compiled JavaScript output on the bottomright. The CoffeeScript is editable!
CoffeeScript 2
What’s New In CoffeeScript 2?
The biggest change in CoffeeScript 2 is that now the CoffeeScript compiler produces modern JavaScript syntax (ES6, or ES2015 and later). A CoffeeScript becomes a JS , a CoffeeScript becomes a JS and so on. Major new features in CoffeeScript 2 include async functions and JSX. You can read more in the announcement.
There are very few breaking changes from CoffeeScript 1.x to 2; we hope the upgrade process is smooth for most projects.
Compatibility
Most modern JavaScript features that CoffeeScript supports can run natively in Node 7.6+, meaning that Node can run CoffeeScript’s output without any further processing required. Here are some notable exceptions:
This list may be incomplete, and excludes versions of Node that support newer features behind flags; please refer to node.green for full details. You can run the tests in your browser to see what your browser supports. It is your responsibility to ensure that your runtime supports the modern features you use; or that you transpile your code. When in doubt, transpile.
Installation
The command-line version of is available as a Node.js utility, requiring Node 6 or later. The core compiler however, does not depend on Node, and can be run in any JavaScript environment, or in the browser (see Try CoffeeScript).
To install, first make sure you have a working copy of the latest stable version of Node.js. You can then install CoffeeScript globally with npm:
This will make the and commands available globally.
If you are using CoffeeScript in a project, you should install it locally for that project so that the version of CoffeeScript is tracked as one of your project’s dependencies. Within that project’s folder:
The and commands will first look in the current folder to see if CoffeeScript is installed locally, and use that version if so. This allows different versions of CoffeeScript to be installed globally and locally.
If you plan to use the option (see Transpilation) you will need to also install either globally or locally, depending on whether you are running a globally or locally installed version of CoffeeScript.
Usage
Command Line
Once installed, you should have access to the command, which can execute scripts, compile files into , and provide an interactive REPL. The command takes the following options:
| Option | Description |
|---|---|
| Compile a script into a JavaScript file of the same name. | |
| Pipe the CoffeeScript compiler’s output through Babel before saving or running the generated JavaScript. Requires to be installed, and options to pass to Babel in a file or a with a key in the path of the file or folder to be compiled. See Transpilation. | |
| Generate source maps alongside the compiled JavaScript files. Adds directives to the JavaScript as well. | |
| Just like , but include the source map directly in the compiled JavaScript files, rather than in a separate file. | |
| Launch an interactive CoffeeScript session to try short snippets. Identical to calling with no arguments. | |
| Write out all compiled JavaScript files into the specified directory. Use in conjunction with or . | |
| Watch files for changes, rerunning the specified command when any file is updated. | |
| Instead of writing out the JavaScript as a file, print it directly to stdout. | |
| Pipe in CoffeeScript to STDIN and get back JavaScript over STDOUT. Good for use with processes written in other languages. An example: | |
| Parses the code as Literate CoffeeScript. You only need to specify this when passing in code directly over stdio, or using some sort of extension-less file name. | |
| Compile and print a little snippet of CoffeeScript directly from the command line. For example: | |
| the given module before starting the REPL or evaluating the code given with the flag. | |
| Compile the JavaScript without the top-level function safety wrapper. | |
| Suppress the “Generated by CoffeeScript” header. | |
| The executable has some useful options you can set, such as , , , and . Use this flag to forward options directly to Node.js. To pass multiple flags, use multiple times. | |
| Generate an abstract syntax tree of nodes of the CoffeeScript. Used for integrating with JavaScript build tools. | |
| Instead of parsing the CoffeeScript, just lex it, and print out the token stream. Used for debugging the compiler. | |
| Instead of compiling the CoffeeScript, just lex and parse it, and print out the parse tree. Used for debugging the compiler. |
Examples:
- Compile a directory tree of files in into a parallel tree of files in :
- Watch a file for changes, and recompile it every time the file is saved:
- Concatenate a list of files into a single script:
- Print out the compiled JS from a one-liner:
- All together now, watch and recompile an entire project as you work on it:
- Start the CoffeeScript REPL ( to exit, for multi-line):
To use , see Transpilation.
Node.js
If you’d like to use Node.js’ CommonJS to CoffeeScript files, e.g. , you must first “register” CoffeeScript as an extension:
If you want to use the compiler’s API, for example to make an app that compiles strings of CoffeeScript on the fly, you can the full module:
The method has the signature where is a string of CoffeeScript code, and the optional is an object with some or all of the following properties:
- , boolean: if true, a source map will be generated; and instead of returning a string, will return an object of the form .
- , boolean: if true, output the source map as a base64-encoded string in a comment at the bottom.
- , string: the filename to use for the source map. It can include a path (relative or absolute).
- , boolean: if true, output without the top-level function safety wrapper.
- , boolean: if true, output the header.
- , object: if set, this must be an object with the options to pass to Babel. See Transpilation.
- , boolean: if true, return an abstract syntax tree of the input CoffeeScript source code.
Transpilation
CoffeeScript 2 generates JavaScript that uses the latest, modern syntax. The runtime or browsers where you want your code to run might not support all of that syntax. In that case, we want to convert modern JavaScript into older JavaScript that will run in older versions of Node or older browsers; for example, into . This is done via transpilers like Babel, Bublé or Traceur Compiler.
Quickstart
From the root of your project:
Transpiling with the CoffeeScript compiler
To make things easy, CoffeeScript has built-in support for the popular Babel transpiler. You can use it via the command-line option or the Node API option. To use either, must be installed in your project:
Or if you’re running the command outside of a project folder, using a globally-installed module, needs to be installed globally:
By default, Babel doesn’t do anything—it doesn’t make assumptions about what you want to transpile to. You need to provide it with a configuration so that it knows what to do. One way to do this is by creating a file in the folder containing the files you’re compiling, or in any parent folder up the path above those files. (Babel supports other ways, too.) A minimal file would be just . This implies that you have installed :
See Babel’s website to learn about presets and plugins and the multitude of options you have. Another preset you might need is if you’re using JSX with React (JSX can also be used with other frameworks).
Once you have and (or other presets or plugins) installed, and a file (or other equivalent) in place, you can use to pipe CoffeeScript’s output through Babel using the options you’ve saved.
If you’re using CoffeeScript via the Node API, where you call with a string to be compiled and an object, the key of the object should be the Babel options:
You can also transpile CoffeeScript’s output without using the option, for example as part of a build chain. This lets you use transpilers other than Babel, and it gives you greater control over the process. There are many great task runners for setting up JavaScript build chains, such as Gulp, Webpack, Grunt and Broccoli.
Polyfills
Note that transpiling doesn’t automatically supply polyfills for your code. CoffeeScript itself will output if you use the operator, or destructuring or spread/rest syntax; and if you use a bound () method in a class. Both are supported in Internet Explorer 9+ and all more recent browsers, but you will need to supply polyfills if you need to support Internet Explorer 8 or below and are using features that would cause these methods to be output. You’ll also need to supply polyfills if your own code uses these methods or another method added in recent versions of JavaScript. One polyfill option is , though there are many otherstrategies.
Language Reference
This reference is structured so that it can be read from top to bottom, if you like. Later sections use ideas and syntax previously introduced. Familiarity with JavaScript is assumed. In all of the following examples, the source CoffeeScript is provided on the left, and the direct compilation into JavaScript is on the right.
Many of the examples can be run (where it makes sense) by pressing the▶button on the right. The CoffeeScript on the left is editable, and the JavaScript will update as you edit.
First, the basics: CoffeeScript uses significant whitespace to delimit blocks of code. You don’t need to use semicolons to terminate expressions, ending the line will do just as well (although semicolons can still be used to fit multiple expressions onto a single line). Instead of using curly braces to surround blocks of code in functions, if-statements, switch, and try/catch, use indentation.
You don’t need to use parentheses to invoke a function if you’re passing arguments. The implicit call wraps forward to the end of the line or block expression.
→
Functions
Functions are defined by an optional list of parameters in parentheses, an arrow, and the function body. The empty function looks like this:
Functions may also have default values for arguments, which will be used if the incoming argument is missing ().
Strings
Like JavaScript and many other languages, CoffeeScript supports strings as delimited by the or characters. CoffeeScript also supports string interpolation within -quoted strings, using . Single-quoted strings are literal. You may even use interpolation in object keys.
Multiline strings are allowed in CoffeeScript. Lines are joined by a single space unless they end with a backslash. Indentation is ignored.
Block strings, delimited by or , can be used to hold formatted or indentation-sensitive text (or, if you just don’t feel like escaping quotes and apostrophes). The indentation level that begins the block is maintained throughout, so you can keep it all aligned with the body of your code.
Double-quoted block strings, like other double-quoted strings, allow interpolation.
Objects and Arrays
The CoffeeScript literals for objects and arrays look very similar to their JavaScript cousins. When each property is listed on its own line, the commas are optional. Objects may be created using indentation instead of explicit braces, similar to YAML.
CoffeeScript has a shortcut for creating objects when you want the key to be set with a variable of the same name. Note that the and are required for this shorthand.
Comments
In CoffeeScript, comments are denoted by the character to the end of a line, or from to the next appearance of . Comments are ignored by the compiler, though the compiler makes its best effort at reinserting your comments into the output JavaScript after compilation.
Inline comments make type annotations possible.
Lexical Scoping and Variable Safety
The CoffeeScript compiler takes care to make sure that all of your variables are properly declared within lexical scope — you never need to write yourself.
Notice how all of the variable declarations have been pushed up to the top of the closest scope, the first time they appear. is not redeclared within the inner function, because it’s already in scope; within the function, on the other hand, should not be able to change the value of the external variable of the same name, and therefore has a declaration of its own.
Because you don’t have direct access to the keyword, it’s impossible to shadow an outer variable on purpose, you may only refer to it. So be careful that you’re not reusing the name of an external variable accidentally, if you’re writing a deeply nested function.
Although suppressed within this documentation for clarity, all CoffeeScript output (except in files with or statements) is wrapped in an anonymous function: . This safety wrapper, combined with the automatic generation of the keyword, make it exceedingly difficult to pollute the global namespace by accident. (The safety wrapper can be disabled with the option, and is unnecessary and automatically disabled when using modules.)
If you’d like to create top-level variables for other scripts to use, attach them as properties on ; attach them as properties on the object in CommonJS; or use an statement. If you’re targeting both CommonJS and the browser, the existential operator (covered below), gives you a reliable way to figure out where to add them: .
Since CoffeeScript takes care of all variable declaration, it is not possible to declare variables with ES2015’s or . This is intentional; we feel that the simplicity gained by not having to think about variable declaration outweighs the benefit of having three separate ways to declare variables.
If, Else, Unless, and Conditional Assignment
/ statements can be written without the use of parentheses and curly brackets. As with functions and other block expressions, multi-line conditionals are delimited by indentation. There’s also a handy postfix form, with the or at the end.
CoffeeScript can compile statements into JavaScript expressions, using the ternary operator when possible, and closure wrapping otherwise. There is no explicit ternary statement in CoffeeScript — you simply use a regular statement on a single line.
Splats, or Rest Parameters/Spread Syntax
The JavaScript object is a useful way to work with functions that accept variable numbers of arguments. CoffeeScript provides splats , both for function definition as well as invocation, making variable numbers of arguments a little bit more palatable. ES2015 adopted this feature as their rest parameters.
Splats also let us elide array elements…
…and object properties.
In ECMAScript this is called spread syntax, and has been supported for arrays since ES2015 and objects since ES2018.
Loops and Comprehensions
Most of the loops you’ll write in CoffeeScript will be comprehensions over arrays, objects, and ranges. Comprehensions replace (and compile into) loops, with optional guard clauses and the value of the current array index. Unlike for loops, array comprehensions are expressions, and can be returned and assigned.
HAProxy
Quick links
Quick NewsRecent News
Description
Main features
Supported Platforms
Performance
Reliability
Security
Download
Documentation
Live demo
They use it!
Enterprise Features
Third party extensions
Commercial Support
Add-on features
Other Solutions
Contacts
External links
Discussions
Slack channel
Mailing list
10GbE load-balancing (updated)
Contributions
Coding style
Open Issues
Known bugs
HATop: Ncurses Interface
Herald: load feedback agent
haproxystats: stats collection
Alpine-based Docker images
Debian-based Docker images
RHEL-based Docker images
Debian/Ubuntu packages
 visitors online
visitors online 

Thanks for your support !





Latest versions
Quick News
August 13th, 2020 : HAProxyConf 2020 postponed- As most already expected it, the HAProxyConf 2020 which was initially planned around November will be postponed to a yet unknown date in 2021 depending on how the situation evolves regarding the pandemic. At this point it's useless to forecast anything, so we'll start to announce it upfront once we have a better visibility of what is possible. In the mean time, if you're impatient, please be aware that all the 2019 talks are available on https://www.haproxyconf.com/2019/presentations/.
July 7th, 2020 : HAProxy 2.2.0 is ready!
- HAProxy 2.2 is tha latest LTS release, delivered few weeks late, but for good given that many early bugs were addressed during this time! New features include runtime certificate addition and crtlist management, dynamic error pages and return statements, logging over TCP, refined idle connection pools saving server resources, extensible health checks, improved I/O processing and scheduling for even lower latency processing, even more debugging information. Please check the announce here for more details.
November 25th, 2019 : HAProxy 2.1.0 is out!
- Delivered on time, for once, proving that our new development process works better. In short this provides hot-update of certificates, FastCGI to backends, better performance, more debugging capabilities and some extra goodies. Please check the announce here for more details.
Older news...
Description
HAProxy is a free, very fast and reliable solution offering high availability, load balancing, and proxying for TCP and HTTP-based applications. It is particularly suited for very high traffic web sites and powers quite a number of the world's most visited ones. Over the years it has become the de-facto standard opensource load balancer, is now shipped with most mainstream Linux distributions, and is often deployed by default in cloud platforms. Since it does not advertise itself, we only know it's used when the admins report it :-)
Its mode of operation makes its integration into existing architectures very easy and riskless, while still offering the possibility not to expose fragile web servers to the net, such as below :
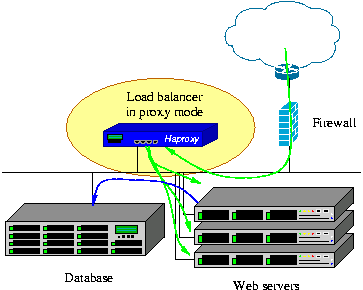
We always support at least two active versions in parallel and an extra old one in critical fixes mode only. The currently supported versions are :
- version 2.2 : runtime certificate additions, improved idle connection management, logging over TCP, HTTP "return" directive, errorfile templates, TLSv1.2 by default, extensible health-checks
- version 2.1 : improved I/Os and multi-threading, FastCGI, runtime certificate updates, HTX-only, improved debugging, removal of obsolete keywords
- version 2.0 : gRPC, layer 7 retries, process manager, SSL peers, log load balancing/sampling, end-to-end TCP fast-open, automatic settings (maxconn, threads, HTTP reuse, pools), ...
- version 1.9 : improved multi-threading, end-to-end HTTP/2, connection pools, queue priority control, stdout logging, ...
- version 1.8 : multi-threading, HTTP/2, cache, on-the fly server addition/removal, seamless reloads, DNS SRV, hardware SSL engines, ...
- version 1.7 : added server hot reconfiguration, content processing agents, multi-type certs, ...
- version 1.6 : added DNS resolution support, HTTP connection multiplexing, full stick-table replication, stateless compression, ...
- version 1.5 : added SSL, IPv6, keep-alive, DDoS protection, ...
Main features
Each version brought its set of features on top of the previous one. Upwards compatibility is a very important aspect of HAProxy, and even version 1.5 is able to run with configurations made for version 1.0 13 years before. Version 1.6 dropped a few long-deprecated keywords and suggests alternatives. The most differenciating features of each version are listed below :
- version 1.5, released in 2014 This version further expands 1.4 with 4 years of hard work : native SSL support on both sides with SNI/NPN/ALPN and OCSP stapling, IPv6 and UNIX sockets are supported everywhere, full HTTP keep-alive for better support of NTLM and improved efficiency in static farms, HTTP/1.1 compression (deflate, gzip) to save bandwidth, PROXY protocol versions 1 and 2 on both sides, data sampling on everything in request or response, including payload, ACLs can use any matching method with any input sample maps and dynamic ACLs updatable from the CLI stick-tables support counters to track activity on any input sample custom format for logs, unique-id, header rewriting, and redirects, improved health checks (SSL, scripted TCP, check agent, ...), much more scalable configuration supports hundreds of thousands of backends and certificates without sweating
- version 1.4, released in 2010 This version has brought its share of new features over 1.3, most of which were long awaited : client-side keep-alive to reduce the time to load heavy pages for clients over the net, TCP speedups to help the TCP stack save a few packets per connection, response buffering for an even lower number of concurrent connections on the servers, RDP protocol support with server stickiness and user filtering, source-based stickiness to attach a source address to a server, a much better stats interface reporting tons of useful information, more verbose health checks reporting precise statuses and responses in stats and logs, traffic-based health to fast-fail a server above a certain error threshold, support for HTTP authentication for any request including stats, with support for password encryption, server management from the CLI to enable/disable and change a server's weight without restarting haproxy, ACL-based persistence to maintain or disable persistence based on ACLs, regardless of the server's state, log analyzer to generate fast reports from logs parsed at 1 Gbyte/s,
- version 1.3, released in 2006 This version has brought a lot of new features and improvements over 1.2, among which content switching to select a server pool based on any request criteria, ACL to write content switching rules, wider choice of load-balancing algorithms for better integration, content inspection allowing to block unexpected protocols, transparent proxy under Linux, which allows to directly connect to the server using the client's IP address, kernel TCP splicing to forward data between the two sides without copy in order to reach multi-gigabit data rates, layered design separating sockets, TCP and HTTP processing for more robust and faster processing and easier evolutions, fast and fair scheduler allowing better QoS by assigning priorities to some tasks, session rate limiting for colocated environments, etc...
Version 1.2 has been in production use since 2006 and provided an improved performance level on top of 1.1. It is not maintained anymore, as most of its users have switched to 1.3 a long time ago. Version 1.1, which has been maintaining critical sites online since 2002, is not maintained anymore either. Users should upgrade to 1.4 or 1.5.
Supported platforms
HAProxy is known to reliably run on the following OS/Platforms :
- Linux 2.4 on x86, x86_64, Alpha, Sparc, MIPS, PARISC
- Linux 2.6-5.x on x86, x86_64, ARM, AARCH64, MIPS, Sparc, PPC64
- Solaris 8/9 on UltraSPARC 2 and 3
- Solaris 10 on Opteron and UltraSPARC
- FreeBSD 4.10 - current on x86
- OpenBSD 3.1 to -current on i386, amd64, macppc, alpha, sparc64 and VAX (check the ports)
- AIX 5.1 - 5.3 on Power™ architecture
Highest performance is achieved with modern operating systems supporting scalable polling mechanisms such as epoll on Linux 2.6/3.x or kqueue on FreeBSD and OpenBSD. This requires haproxy version newer than 1.2.5. Fast data transfers are made possible on Linux 3.x using TCP splicing and haproxy 1.4 or 1.5. Forwarding rates of up to 40 Gbps have already been achieved on such platforms after a very careful tuning. While Solaris and AIX are supported, they should not be used if extreme performance is required.
Current typical 1U servers equipped with a dual-core Opteron or Xeon generally achieve between 15000 and 40000 hits/s and have no trouble saturating 2 Gbps under Linux.
Performance
[ warning: information in this section dates 2007, things have improved by an order of magnitude since then ]
Well, since a user's testimony is better than a long demonstration, please take a look at Chris Knight's experience with haproxy saturating a gigabit fiber in 2007 on a video download site. Since then, the performance has significantly increased and the hardware has become much more capable, as my experiments with Myricom's 10-Gig NICs have shown two years later. Now as of 2014, 10-Gig NICs are too limited and are hardly suited for 1U servers since they do rarely provide enough port density to reach speeds above 40-60 Gbps in a 1U server. 100-Gig NICs are coming and I expect to run new series of tests when they are available.
HAProxy involves several techniques commonly found in Operating Systems architectures to achieve the absolute maximal performance :
- a single-process, event-driven model considerably reduces the cost of context switch and the memory usage. Processing several hundreds of tasks in a millisecond is possible, and the memory usage is in the order of a few kilobytes per session while memory consumed in preforked or threaded servers is more in the order of megabytes per process.
- O(1) event checker on systems that allow it (Linux and FreeBSD) allowing instantaneous detection of any event on any connection among tens of thousands.
- Delayed updates to the event checker using a lazy event cache ensures that we never update an event unless absolutely required. This saves a lot of system calls.
- Single-buffering without any data copy between reads and writes whenever possible. This saves a lot of CPU cycles and useful memory bandwidth. Often, the bottleneck will be the I/O busses between the CPU and the network interfaces. At 10-100 Gbps, the memory bandwidth can become a bottleneck too.
- Zero-copy forwarding is possible using the system call under Linux, and results in real zero-copy starting with Linux 3.5. This allows a small sub-3 Watt device such as a Seagate Dockstar to forward HTTP traffic at one gigabit/s.
- MRU memory allocator using fixed size memory pools for immediate memory allocation favoring hot cache regions over cold cache ones. This dramatically reduces the time needed to create a new session.
- Work factoring, such as multiple at once, and the ability to limit the number of per iteration when running in multi-process mode, so that the load is evenly distributed among processes.
- CPU-affinity is supported when running in multi-process mode, or simply to adapt to the hardware and be the closest possible to the CPU core managing the NICs while not conflicting with it.
- Tree-based storage, making heavy use of the Elastic Binary tree I have been developping for several years. This is used to keep timers ordered, to keep the runqueue ordered, to manage round-robin and least-conn queues, to look up ACLs or keys in tables, with only an O(log(N)) cost.
- Optimized timer queue : timers are not moved in the tree if they are postponed, because the likeliness that they are met is close to zero since they're mostly used for timeout handling. This further optimizes the ebtree usage.
- optimized HTTP header analysis : headers are parsed an interpreted on the fly, and the parsing is optimized to avoid an re-reading of any previously read memory area. Checkpointing is used when an end of buffer is reached with an incomplete header, so that the parsing does not start again from the beginning when more data is read. Parsing an average HTTP request typically takes half a microsecond on a fast Xeon E5.
- careful reduction of the number of expensive system calls. Most of the work is done in user-space by default, such as time reading, buffer aggregation, file-descriptor enabling/disabling.
- Content analysis is optimized to carry only pointers to original data and never copy unless the data needs to be transformed. This ensures that very small structures are carried over and that contents are never replicated when not absolutely necessary.
All these micro-optimizations result in very low CPU usage even on moderate loads. And even at very high loads, when the CPU is saturated, it is quite common to note figures like 5% user and 95% system, which means that the HAProxy process consumes about 20 times less than its system counterpart. This explains why the tuning of the Operating System is very important. This is the reason why we ended up building our own appliances, in order to save that complex and critical task from the end-user.
In production, HAProxy has been installed several times as an emergency solution when very expensive, high-end hardware load balancers suddenly failed on Layer 7 processing. Some hardware load balancers still do not use proxies and process requests at the packet level and have a great difficulty at supporting requests across multiple packets and high response times because they do no buffering at all. On the other side, software load balancers use TCP buffering and are insensible to long requests and high response times. A nice side effect of HTTP buffering is that it increases the server's connection acceptance by reducing the session duration, which leaves room for new requests.
There are 3 important factors used to measure a load balancer's performance :
- The session rate
This factor is very important, because it directly determines when the load balancer will not be able to distribute all the requests it receives. It is mostly dependant on the CPU. Sometimes, you will hear about requests/s or hits/s, and they are the same as sessions/s in or with keep-alive disabled. Requests/s with keep-alive enabled is generally much higher (since it significantly reduces system-side work) but is often meaningless for internet-facing deployments since clients often open a large amount of connections and do not send many requests per connection on avertage. This factor is measured with varying object sizes, the fastest results generally coming from empty objects (eg: or response codes). Session rates around 100,000 sessions/s can be achieved on Xeon E5 systems in 2014. - The session concurrency
This factor is tied to the previous one. Generally, the session rate will drop when the number of concurrent sessions increases (except with the or polling mechanisms). The slower the servers, the higher the number of concurrent sessions for a same session rate. If a load balancer receives 10000 sessions per second and the servers respond in 100 ms, then the load balancer will have 1000 concurrent sessions. This number is limited by the amount of memory and the amount of file-descriptors the system can handle. With 16 kB buffers, HAProxy will need about 34 kB per session, which results in around 30000 sessions per GB of RAM. In practise, socket buffers in the system also need some memory and 20000 sessions per GB of RAM is more reasonable. Layer 4 load balancers generally announce millions of simultaneous sessions because they need to deal with the TIME_WAIT sockets that the system handles for free in a proxy. Also they don't process any data so they don't need any buffer. Moreover, they are sometimes designed to be used in Direct Server Return mode, in which the load balancer only sees forward traffic, and which forces it to keep the sessions for a long time after their end to avoid cutting sessions before they are closed. - The data forwarding rate
This factor generally is at the opposite of the session rate. It is measured in Megabytes/s (MB/s), or sometimes in Gigabits/s (Gbps). Highest data rates are achieved with large objects to minimise the overhead caused by session setup and teardown. Large objects generally increase session concurrency, and high session concurrency with high data rate requires large amounts of memory to support large windows. High data rates burn a lot of CPU and bus cycles on software load balancers because the data has to be copied from the input interface to memory and then back to the output device. Hardware load balancers tend to directly switch packets from input port to output port for higher data rate, but cannot process them and sometimes fail to touch a header or a cookie. Haproxy on a typical Xeon E5 of 2014 can forward data up to about 40 Gbps. A fanless 1.6 GHz Atom CPU is slightly above 1 Gbps.
A load balancer's performance related to these factors is generally announced for the best case (eg: empty objects for session rate, large objects for data rate). This is not because of lack of honnesty from the vendors, but because it is not possible to tell exactly how it will behave in every combination. So when those 3 limits are known, the customer should be aware that it will generally perform below all of them. A good rule of thumb on software load balancers is to consider an average practical performance of half of maximal session and data rates for average sized objects.
You might be interested in checking the 10-Gigabit/s page.
Reliability - keeping high-traffic sites online since 2002
Being obsessed with reliability, I tried to do my best to ensure a total continuity of service by design. It's more difficult to design something reliable from the ground up in the short term, but in the long term it reveals easier to maintain than broken code which tries to hide its own bugs behind respawning processes and tricks like this.
In single-process programs, you have no right to fail : the smallest bug will either crash your program, make it spin like mad or freeze. There has not been any such bug found in stable versions for the last 13 years, though it happened a few times with development code running in production.
HAProxy has been installed on Linux 2.4 systems serving millions of pages every day, and which have only known one reboot in 3 years for a complete OS upgrade. Obviously, they were not directly exposed to the Internet because they did not receive any patch at all. The kernel was a heavily patched 2.4 with Robert Love's patches to support time wrap-around at 497 days (which happened twice). On such systems, the software cannot fail without being immediately noticed !
Right now, it's being used in many Fortune 500 companies around the world to reliably serve billions of pages per day or relay huge amounts of money. Some people even trust it so much that they use it as the default solution to solve simple problems (and I often tell them that they do it the dirty way). Such people sometimes still use versions 1.1 or 1.2 which sees very limited evolutions and which targets mission-critical usages. HAProxy is really suited for such environments because the indicators it returns provide a lot of valuable information about the application's health, behaviour and defects, which are used to make it even more reliable. Version 1.3 has now received far more testing than 1.1 and 1.2 combined, so users are strongly encouraged to migrate to a stable 1.3 or 1.4 for mission-critical usages.
As previously explained, most of the work is executed by the Operating System. For this reason, a large part of the reliability involves the OS itself. Latest versions of Linux 2.4 have been known for offering the highest level of stability ever. However, it requires a bunch of patches to achieve a high level of performance, and this kernel is really outdated now so running it on recent hardware will often be difficult (though some people still do). Linux 2.6 and 3.x include the features needed to achieve this level of performance, but old LTS versions only should be considered for really stable operations without upgrading more than once a year. Some people prefer to run it on Solaris (or do not have the choice). Solaris 8 and 9 are known to be really stable right now, offering a level of performance comparable to legacy Linux 2.4 (without the epoll patch). Solaris 10 might show performances closer to early Linux 2.6. FreeBSD shows good performance but pf (the firewall) eats half of it and needs to be disabled to come close to Linux. OpenBSD sometimes shows socket allocation failures due to sockets staying in state when client suddenly disappears. Also, I've noticed that hot reconfiguration does not work under OpenBSD.
The reliability can significantly decrease when the system is pushed to its limits. This is why finely tuning the is important. There is no general rule, every system and every application will be specific. However, it is important to ensure that the system will never run out of memory and that it will never swap. A correctly tuned system must be able to run for years at full load without slowing down nor crashing.
Security - Not even one intrusion in 13 years
Security is an important concern when deploying a software load balancer. It is possible to harden the OS, to limit the number of open ports and accessible services, but the load balancer itself stays exposed. For this reason, I have been very careful about programming style. Vulnerabilities are very rarely encountered on haproxy, and its architecture significantly limits their impact and often allows easy workarounds. Its remotely unpredictable even processing makes it very hard to reliably exploit any bug, and if the process ever crashes, the bug is discovered. All of them were discovered by reverse-analysis of an accidental crash BTW.
Anyway, much care is taken when writing code to manipulate headers. Impossible state combinations are checked and returned, and errors are processed from the creation to the death of a session. A few people around the world have reviewed the code and suggested cleanups for better clarity to ease auditing. By the way, I'm used to refuse patches that introduce suspect processing or in which not enough care is taken for abnormal conditions.
I generally suggest starting HAProxy as because it can then jail itself in a chroot and drop all of its privileges before starting the instances. This is not possible if it is not started as because only can execute , contrary to what some admins believe.
Logs provide a lot of information to help maintain a satisfying security level. They are commonly sent over because once chrooted, the UNIX socket is unreachable, and it must not be possible to write to a file. The following information are particularly useful :
- source IP and port of requestor make it possible to find their origin in firewall logs ;
- session set up date generally matches firewall logs, while tear down date often matches proxies dates ;
- proper request encoding ensures the requestor cannot hide non-printable characters, nor fool a terminal.
- arbitrary request and response header and cookie capture help to detect scan attacks, proxies and infected hosts.
- timers help to differentiate hand-typed requests from browsers's.
HAProxy also provides regex-based header control. Parts of the request, as well as request and response headers can be denied, allowed, removed, rewritten, or added. This is commonly used to block dangerous requests or encodings (eg: the Apache Chunk exploit), and to prevent accidental information leak from the server to the client. Other features such as checking ensure that no sensible information gets accidentely cached by an upstream proxy consecutively to a bug in the application server for example.
Download
The source code is covered by GPL v2. Source code can be downloaded right here for some old versions :
- Development version (2.2) :
- Latest LTS version (2.2) :
- Previous version (2.1) :
- Previous LTS version (2.0) :
- Previous version (1.9) :
- Previous version (1.8) :
- Older version (1.7) :
- Older version (1.6) :
- Oldest version (1.5) :
- Unmaintained version (1.4) :
- Unmaintained version (1.3) :
- Unmaintained branch (1.2) :
- Various Patches :
- Some patches for Stunnel by HAProxy Technologies (formerly Exceliance), such X-Forwarded-For, send-proxy, unix-sockets, multi-process SSL session synchronization, transparent binding and performance improvements.
- http://www.haproxy.com/download/free/patches/linux/epoll-2.4/ : kernel patches to enable on standard Linux 2.4 kernels and on Red Hat Enterprise Linux 3.
- HAProxy Technologies' public patch repository for other patches (stud, stunnel, linux, keepalived, ...)
- Browse directory for other (outdated) patches.
- Browsable directory for other files (not only patches)
Documentation
There are three types of documentation now : the Reference Manual which explains how to configure HAProxy but which is outdated, the Architecture Guide which will guide you through various typical setups, and the new Configuration Manual which replaces the Reference Manual with more a explicit configuration language explanation. The official documentation is the pure-text one provided with the sources. However, Cyril Bonté's automated conversion to HTML is much easier to use and constantly up to date, so it is the preferred one when available.
- Reference Manual for version 2.3 (development) :
- Reference Manual for version 2.2 (Stable) :
- Reference Manual for version 2.1 (Stable) :
- Reference Manual for version 2.0 (Stable (LTS)) :
- Reference Manual for version 1.9 (unmaintained) :
- Reference Manual for version 1.8 (Stable (LTS)) :
- Reference Manual for version 1.7 (Critical fixes only) :
- Reference Manual for version 1.6 (Critical fixes only) :
- Reference Manual for version 1.5 (unmaintained) :
- Reference Manual for version 1.4 (unmaintained) :
- Reference Manual for version 1.3 (unmaintained) :
- Reference Manual for version 1.2 (unmaintained) :
- Reference Manual for version 1.1 (unmaintained) :
 : Architecture Guide
: Architecture Guide - Article on Load Balancing (HTML version) : worth reading for people who don't know what type of load balancer they need
In addition to Cyril's HTML converter above, an automated format converter is being developed by Pavel Lang. At the time of writing these lines, it is able to produce a PDF from the documentation, and some heavy work is ongoing to support other output formats. Please consult the project's page for more information. Here's an example of what it is able to do on version 1.5 configuration manual.
Commercial Support and availability
If you think you don't have the time and skills to setup and maintain a free load balancer, or if you're seeking for commercial support to satisfy your customers or your boss, you have the following options :
- contact HAProxy Technologies to hire some professional services or subscribe a support contract ;
- install HAProxy Enterprise Edition (HAPEE), which is a long-term maintained HAProxy package accompanied by a well-polished collection of software, scripts, configuration files and documentation which significantly simplifies the setup and maintenance of a completely operational solution ; it is particularly suited to Cloud environments where deployments must be fast.
- try an ALOHA appliance (hardware or virtual), which will even save you from having to worry about the system, hardware and from managing a Unix-like system.
Add-on features and contributions
Some happy users have contributed code which may or may not be included. Others spent a long time analysing the code, and there are some who maintain ports up to date. The most difficult internal changes have been contributed in the form of paid time by some big customers who can afford to pay a developer for several months working on an opensource project. Unfortunately some of them do not want to be listed, which is the case for the largest of them.
Some contributions were developped and not merged, most often by lack of sign of interest from the users or simply because they overlap with some pending changes in a way that could make it harder to maintain future compatibility.
- Geolocation support
- sFlow support
Quite some time ago now, Cyril Bonté contacted me about a very interesting feature he has developped, initially for 1.4, and which now supports both 1.4 and 1.5. This feature is Geolocation, which many users have been asking for for a long time, and this one does not require to split the IP files by country codes. In fact it's extremely easy and convenient to configure.
The feature was not merged yet because it does for a specific purpose (GeoIP) what we wanted to have for a more general use (map converters, session variables, and use of variables in the redirect URLs), which will allow the same features to be implemented with more flexibility (eg: extract the IP from a header, or pass the country code and/or AS number to a backend server, etc...). Cyril was very receptive to these arguments and accepted to maintain his patchset out of tree waiting for the features to be implemented (Update: 1.5-dev20 with maps now make this possible). Cyril's code is well maintained and used in production so there is no risk in using it on 1.4, except the fact that the configuration statements will change a bit once you upgrade to 1.5.
The code and documentation are available here : https://github.com/cbonte/haproxy-patches/wiki/Geolocation
Neil Mckee posted a patch to the list in early 2013, and unfortunately this patch did not receive any sign of interest nor feedback, which is sad considering the amount of work that was done. I personally am clueless about sFlow and expressed my skepticism to Neil about the benefits of sampling some HTTP traffic when you can get much more detailed informations for free with existing logs.
Neil kindly responded with the following elements :
- I agree that the logging you already have in haproxy is more flexible and detailed, and I acknowledge that the benefit of exporting sFlow-HTTP records is not immediately obvious.
The value that sFlow brings is that the measurements are standard, and are designed to integrate seamlessly with sFlow feeds from switches, routers, servers and applications to provide a comprehensive end to end picture of the performance of large scale multi-tier systems. So the purpose is not so much to troubleshoot haproxy in isolation, but to analyze the performance of the whole system that haproxy is part of.
Perhaps the best illustration of this is the 1-in-N sampling feature. If you configure sampling.http to be, say, 1-in-400 then you might only see a handful of sFlow records per second from an haproxy instance, but that is enough to tell you a great deal about what is going on -- in real time. And the data will not bury you even if you have a bank of load-balancers, hundreds of web-servers, a huge memcache-cluster and a fast network interconnect all contributing their own sFlow feeds to the same analyzer.
Even after that explanation, no discussion emerged on the subject on the list, so I guess there is little interest among users for now. I suspect that sFlow is probably more deployed among network equipments than application layer equipments, which could explain this situation. The code is large (not huge though) and I am not convinced about the benefits of merging it and maintaining it if nobody shows even a little bit of interest. Thus for now I prefer to leave it out of tree. Neil has posted it on GitHub here : https://github.com/sflow/haproxy.
Please, if you do use this patch, report your feedback to the mailing list, and invest some time helping with the code review and testing.
This table enumerates all known significant contributions that led to version 1.4, as well as proposed fundings and features yet to be developped but waiting for spare time. It is not more up to date though.
Some older code contributions which possibly do not appear in the table above are still listed here.
- Application Cookies
Aleksandar Lazic and Klaus Wagner implemented this feature which was merged in 1.2. It allows the proxy to learn cookies sent by the server to the client, and to find it back in the URL to direct the client to the right server. The learned cookies are automatically purged after some inactive time.
- Least Connections load balancing algorithm
This patch for haproxy-1.2.14 was submitted by Oleksandr Krailo. It implements a basic least connection algorithm. I've not merged this version into 1.3 because of scalability concerns, but I'm leaving it here for people who are tempted to include it into version 1.2, and the patch is really clean.
- Soft Server-Stop
Aleksandar Lazic sent me this patch against 1.1.28 which in fact does two things. The first interesting part allows one to write a file enumerating servers which will have to be stopped, and then sending a signal to the running proxy to tell it to re-read the file and stop using these servers. This will not be merged into mainline because it has indirect implications on security since the running process will have to access a file on the file-system, while current version can run in a chrooted, empty, read-only directory. What is really needed is a way to send commands to the running process. However, I understand that some people might need this feature, so it is provided here. The second part of the patch has been merged. It allowed both an active and a backup server to share a same cookie. This may sound obvious but it was not possible earlier.
Usage: Aleks says that you just have to write the server names that you want to stop in the file, then the running process. I have not tested it though.
- Server Weight
Sébastien Brize sent me this patch against 1.1.27 which adds the 'weight' option to a server to provide smoother balancing between fast and slow servers. It is available here because there may be other people looking for this feature in version 1.1.
I did not include this change because it has a side effect that with high or unequal weights, some servers might receive lots of consecutive requests. A different concept to provide a smooth and fair balancing has been implemented in 1.2.12, which also supports weighted hash load balancing.Usage: specify "" on a server line.
Note: configurations written with this patch applied will normally still work with future 1.2 versions. - IPv6 support for 1.1.27
I implemented IPv6 support on client side for 1.1.27, and merged it into haproxy-1.2. Anyway, the patch is still provided here for people who want to experiment with IPv6 on HAProxy-1.1.
- Other patches
Please browse the directory for other useful contributions.
Other Solutions
If you don't need all of HAProxy's features and are looking for a simpler solution, you may find what you need here :
- Linux Virtual Servers (LVS)
Very fast layer 3/4 load balancing merged in Linux 2.4 and 2.6 kernels. Should be coupled with Keepalived to monitor servers. This generally is the solution embedded by default in most IP-based load balancers. - Nginx ("engine X")
Nginx is an excellent piece of software. Initially it's a very fast and reliable web server, but it has grown into a full-featured proxy which can also offer load-balancing capabilities. Nginx's load balancing features are less advanced than haproxy's but it can do extra things (eg: caching, running FCGI apps), which explains why they are very commonly found together. I strongly recommend it to whoever needs a fast, reliable and flexible web server ! - Pound
Pound is very small and reasonably good. It aims at remaining small and auditable prior to being fast. It used to support SSL and keep-alive before HAProxy. Its configuration file is small and simple. It's thread-based, but can be a simpler alternative to HAProxy for a small site when the flexibility and performance of HAProxy are not required. - Pen
Pen is a very simple load balancer for TCP protocols. It supports source IP-based persistence for up to 2048 clients. Supports IP-based ACLs. Uses and supports higher loads than Pound but will not scale very well to thousands of simultaneous connections. It's more versatile however, and could be considered as the missing link between HAProxy and socat.
Contacts
Feel free to contact us for any questions or comments :
Some people regularly ask if it is possible to send donations, so I have set up a Paypal account for this. Click here if you want to donate.
An IRC channel for haproxy has been opened on FreeNode (but don't seek me there, I'm not) :
External links
Here are some links to possibly useful external contents I gathered on the net. I have found most of them due to their link to haproxy's site ;-)
- Health Checks and Graceful Degradation in Distributed Systems
- haproxy-auth-request: HTTP access control using subrequests
- Utiliser HAProxy pour profiter d'HTTP/2 (FR)
- HAProxy in 2018 - A load balancer with HTTP/2 and dynamic reconfig
- GlusterFS: Configuration and Setup w/ NFS-Ganesha for an HA NFS Cluster
- Service discovery at Stripe
- High Availability with HAProxy and Keepalived in AWS
- How we fine-tuned HAProxy to achieve 2,000,000 concurrent SSL connections
- Speeding up SSL - All you need to know about haproxy
- Improving load balancing with a new consistent-hashing algorithm
- ACME validation plugin for HAProxy / Let's Encrypt
- Use HAProxy to load balance 300k concurrent tcp socket connections
- Accelerating SSL Load Balancers with Intel® Xeon® v3 Processors
- Linux networking stack from the ground up (parts 1-5) (useful to whoever wants to know what happens below haproxy)
- Loadbalance your website with haproxy and varnish
- How TubeMogul Handles over One Trillon HTTP Requests a Month
- HAProxy in the era of Microservices
- Making HAProxy 1.5 replication lag aware in MySQL
- MaxCDN: How to Use HAProxy to Handle Traffic Spikes
- Varnish, SSL and HAProxy
- True Zero Downtime HAProxy Reloads
- HAProxy Is Still An Arrow in the Quiver for Those Scaling Apps
- How To Set Up SQL Load Balancing with HAProxy (Webinar)
- HAProxy running on Ubuntu Cloud on Power8, featured by Mark Shuttleworth at IBM Impact 2014 Keynote
- Guidelines for HAProxy termination in AWS
- Marcus Rueckert's talk at osc14
- How Stack Exchange gets the most out of HAProxy
- Open Source Windows service for reporting server load back to HAProxy (load balancer feedback agent).
- Load Balancing Amazon RDS Read Replica's using HAProxy
- Installing HAProxy on pfSense
- MySQL Load Balancing with HAProxy - Tutorial
- HAProxy vs Nginx benchmark for the Eucalyptus Cloud computing Platform
- WebSocket Over SSL: HAProxy, Node.js, Nginx
- Comparison Analysis:Amazon ELB vs HAProxy EC2
- Simple SPDY and NPN Negotiation with HAProxy
- Using HAProxy to Build a More Featureful Elastic Load Balancer
- 3 ways to configure haproxy for websockets
- Segregating services at bitbucket
- Load balancing FTP, by Ben Timby
- Howto setup a haproxy as fault tolerant / high available load balancer for multiple caching web proxies on RHEL/Centos/SL
- Load balancing @Tuenti, by Ricardo Bartolomé
- Benchmarking SSL performance
- Smart Content Switching for News Website
- HA Proxy for Exchange 2010 Deployment & SMTP Restriction
- A more stable MySQL with HAProxy
- Benchmarking HAProxy under VMware : Ubuntu vs FreeBSD
- Stack Overflow: Better rate limiting for all with HAProxy
- Benchmarking Load Balancers in the Cloud
- Using HAProxy for MySQL failover and redundancy
- Setting up a high availability load blancer with haproxy and keepalived on debian lenny
- Configure HAProxy with TPROXY kernel for full transparent proxy
- HAProxy, X-Forwarded-For, GeoIP, KeepAlive
- Load Balancing in Amazon EC2 with HAProxy
- CouchDB Load Balancing and Replication using HAProxy
- Zero-Downtime restarts with HAProxy
- Free your port 80 with HAProxy
- Another comparison of HAProxy and Nginx
- Scaling on EC2
- HAProxy on Opensolaris 2008.05
- Load-Balancing and QoS with HAProxy
- Reviewing Application Health with HAProxy Stats
Leap second
A leap second is a one-second adjustment that is occasionally applied to Coordinated Universal Time (UTC), to accommodate the difference between precise time (as measured by atomic clocks) and imprecise observed solar time (known as UT1 and which varies due to irregularities and long-term slowdown in the Earth's rotation). The UTC time standard, widely used for international timekeeping and as the reference for civil time in most countries, uses precise atomic time and consequently would run ahead of observed solar time unless it is reset to UT1 as needed. The leap second facility exists to provide this adjustment.
Because the Earth's rotation speed varies in response to climatic and geological events,[1] UTC leap seconds are irregularly spaced and unpredictable. Insertion of each UTC leap second is usually decided about six months in advance by the International Earth Rotation and Reference Systems Service (IERS), to ensure that the difference between the UTC and UT1 readings will never exceed 0.9 seconds.[2][3]
This practice has proved disruptive, particularly in the twenty-first century and especially in services that depend on precise time stamping or time-critical process control. The relevant international standards body has been debating whether or not to continue the practice.
History[edit]

About 140 AD, Ptolemy, the Alexandrian astronomer, sexagesimally subdivided both the mean solar day and the true solar day to at least six places after the sexagesimal point, and he used simple fractions of both the equinoctial hour and the seasonal hour, none of which resemble the modern second.[4] Muslim scholars, including al-Biruni in 1000, subdivided the mean solar day into 24 equinoctial hours, each of which was subdivided sexagesimally, that is into the units of minute, second, third, fourth and fifth, creating the modern second as 1⁄60 of 1⁄60 of 1⁄24 = 1⁄86,400 of the mean solar day in the process.[5] With this definition, the second was proposed in 1874 as the base unit of time in the CGS system of units.[6] Soon afterwards Simon Newcomb and others discovered that Earth's rotation period varied irregularly,[7] so in 1952, the International Astronomical Union (IAU) defined the second as a fraction of the sidereal year. In 1955, considering the tropical year to be more fundamental than the sidereal year, the IAU redefined the second as the fraction 1⁄31,556,925.975 of the 1900.0 mean tropical year. In 1956, a slightly more precise value of 1⁄31,556,925.9747 was adopted for the definition of the second by the International Committee for Weights and Measures, and in 1960 by the General Conference on Weights and Measures, becoming a part of the International System of Units (SI).[8]
Eventually, this definition too was found to be inadequate for precise time measurements, so in 1967, the SI second was again redefined as 9,192,631,770 periods of the radiation emitted by a caesium-133 atom in the transition between the two hyperfine levels of its ground state.[9] That value agreed to 1 part in 1010 with the astronomical (ephemeris) second then in use.[10] It was also close to 1⁄86,400 of the mean solar day as averaged between years 1750 and 1892.
However, for the past several centuries, the length of the mean solar day has been increasing by about 1.4–1.7 ms per century, depending on the averaging time.[11][12][13] By 1961, the mean solar day was already a millisecond or two longer than 86,400 SI seconds.[14] Therefore, time standards that change the date after precisely 86,400 SI seconds, such as the International Atomic Time (TAI), will get increasingly ahead of time standards tied to the mean solar day, such as Universal Time (UT1).
When the Coordinated Universal Time standard was instituted in 1960, based on atomic clocks, it was felt necessary to maintain agreement with the GMT time of day, which, until then, had been the reference for broadcast time services. From 1960 to 1971, the rate of UTC atomic clocks was slowed by the BIH to remain synchronized with UT2, a practice known as the "rubber second".[15] The rate of UTC was decided at the start of each year, and was slower than the rate of atomic time by −150 parts per 1010 for 1960–1962, by −130 parts per 1010 for 1962–63, by −150 parts per 1010 again for 1964–65, and by −300 parts per 1010 for 1966–1971.[16] Alongside the shift in rate, an occasional 0.1 s step (0.05 s before 1963) was needed. This predominately frequency shifted rate of UTC was broadcast by MSF, WWV, and CHU among other time stations. In 1966, the CCIR approved "stepped atomic time" (SAT), which adjusted atomic time with more frequent 0.2 s adjustments to keep it within 0.1 s of UT2, because it had no rate adjustments.[17] SAT was broadcast by WWVB among other time stations.[16]
In 1972, the leap-second system was introduced so that the UTC seconds could be set exactly equal to the standard SI second, while still maintaining the UTC time of day and changes of UTC date synchronized with those of UT1 (the solar time standard that superseded GMT).[9] By then, the UTC clock was already 10 seconds behind TAI, which had been synchronized with UT1 in 1958, but had been counting true SI seconds since then. After 1972, both clocks have been ticking in SI seconds, so the difference between their displays at any time is 10 seconds plus the total number of leap seconds that have been applied to UTC as of that time; as of June 2020[update], 27 leap seconds have been applied to UTC, so the difference is 10 + 27 = 37 seconds.
Insertion of leap seconds[edit]
| Year | Jun 30 | Dec 31 |
|---|---|---|
| 1972 | +1 | +1 |
| 1973 | 0 | +1 |
| 1974 | 0 | +1 |
| 1975 | 0 | +1 |
| 1976 | 0 | +1 |
| 1977 | 0 | +1 |
| 1978 | 0 | +1 |
| 1979 | 0 | +1 |
| 1980 | 0 | 0 |
| 1981 | +1 | 0 |
| 1982 | +1 | 0 |
| 1983 | +1 | 0 |
| 1984 | 0 | 0 |
| 1985 | +1 | 0 |
| 1986 | 0 | 0 |
| 1987 | 0 | +1 |
| 1988 | 0 | 0 |
| 1989 | 0 | +1 |
| 1990 | 0 | +1 |
| 1991 | 0 | 0 |
| 1992 | +1 | 0 |
| 1993 | +1 | 0 |
| 1994 | +1 | 0 |
| 1995 | 0 | +1 |
| 1996 | 0 | 0 |
| 1997 | +1 | 0 |
| 1998 | 0 | +1 |
| 1999 | 0 | 0 |
| 2000 | 0 | 0 |
| 2001 | 0 | 0 |
| 2002 | 0 | 0 |
| 2003 | 0 | 0 |
| 2004 | 0 | 0 |
| 2005 | 0 | +1 |
| 2006 | 0 | 0 |
| 2007 | 0 | 0 |
| 2008 | 0 | +1 |
| 2009 | 0 | 0 |
| 2010 | 0 | 0 |
| 2011 | 0 | 0 |
| 2012 | +1 | 0 |
| 2013 | 0 | 0 |
| 2014 | 0 | 0 |
| 2015 | +1 | 0 |
| 2016 | 0 | +1 |
| 2017 | 0 | 0 |
| 2018 | 0 | 0 |
| 2019 | 0 | 0 |
| 2020 | 0 | 0 |
| Year | Jun 30 | Dec 31 |
| Total | 11 | 16 |
| 27 | ||
| Current TAI − UTC | ||
| 37 | ||
The scheduling of leap seconds was initially delegated to the Bureau International de l'Heure (BIH), but passed to the International Earth Rotation and Reference Systems Service (IERS) on January 1, 1988. IERS usually decides to apply a leap second whenever the difference between UTC and UT1 approaches 0.6 s, in order to keep the difference between UTC and UT1 from exceeding 0.9 s.
The UTC standard allows leap seconds to be applied at the end of any UTC month, with first preference to June and December and second preference to March and September. As of January 2017[update], all of them have been inserted at the end of either June 30 or December 31. IERS publishes announcements every six months, whether leap seconds are to occur or not, in its "Bulletin C". Such announcements are typically published well in advance of each possible leap second date – usually in early January for June 30 and in early July for December 31.[19][20] Some time signal broadcasts give voice announcements of an impending leap second.
Between 1972 and 2020, a leap second has been inserted about every 21 months, on average. However, the spacing is quite irregular and apparently increasing: there were no leap seconds in the six-year interval between January 1, 1999 and December 31, 2004, but there were nine leap seconds in the eight years 1972–1979.
Unlike leap days, which begin after February 28 23:59:59 local time,[a] UTC leap seconds occur simultaneously worldwide; for example, the leap second on December 31, 2005 23:59:60 UTC was December 31, 2005 18:59:60 (6:59:60 p.m.) in U.S. Eastern Standard Time and January 1, 2006 08:59:60 (a.m.) in Japan Standard Time.
Process[edit]
When it is mandated, a positive leap second is inserted between second 23:59:59 of a chosen UTC calendar date and second 00:00:00 of the following date. The definition of UTC states that the last day of December and June are preferred, with the last day of March or September as second preference, and the last day of any other month as third preference.[21] All leap seconds (as of 2019) have been scheduled for either June 30 or December 31. The extra second is displayed on UTC clocks as 23:59:60. On clocks that display local time tied to UTC, the leap second may be inserted at the end of some other hour (or half-hour or quarter-hour), depending on the local time zone. A negative leap second would suppress second 23:59:59 of the last day of a chosen month, so that second 23:59:58 of that date would be followed immediately by second 00:00:00 of the following date. Since the introduction of leap seconds, the mean solar day has outpaced atomic time only for very brief periods, and has not triggered a negative leap second.
Slowing rotation of the Earth[edit]

Leap seconds are irregularly spaced because the Earth's rotation speed changes irregularly. Indeed, the Earth's rotation is quite unpredictable in the long term, which explains why leap seconds are announced only six months in advance.
A mathematical model of the variations in the length of the solar day was developed by F. R. Stephenson and L. V. Morrison,[13] based on records of eclipses for the period 700 BC to 1623 AD, telescopic observations of occultations for the period 1623 until 1967 and atomic clocks thereafter. The model shows a steady increase of the mean solar day by 1.70 ms(± 0.05 ms) per century, plus a periodic shift of about 4 ms amplitude and period of about 1,500 yr.[13] Over the last few centuries, rate of lengthening of the mean solar day has been about 1.4 ms per century, being the sum of the periodic component and the overall rate.[22]
The main reason for the slowing down of the Earth's rotation is tidal friction, which alone would lengthen the day by 2.3 ms/century.[13] Other contributing factors are the movement of the Earth's crust relative to its core, changes in mantle convection, and any other events or processes that cause a significant redistribution of mass. These processes change the Earth's moment of inertia, affecting the rate of rotation due to conservation of angular momentum. Some of these redistributions increase Earth's rotational speed, shorten the solar day and oppose tidal friction. For example, glacial rebound shortens the solar day by 0.6 ms/century and the 2004 Indian Ocean earthquake is thought to have shortened it by 2.68 microseconds.[23] It is evident from the figure that the Earth's rotation has slowed at a decreasing rate since the initiation of the current system in 1971, and the rate of leap second insertions has therefore been decreasing.
Future of leap seconds[edit]
The TAI and UT1 time scales are precisely defined, the former by atomic clocks (and thus independent of Earth's rotation) and the latter by astronomical observations (that measure actual planetary rotation and thus the solar time at the Greenwich meridian). UTC (on which civil time is usually based) is a compromise, stepping with atomic seconds but periodically reset by a leap second to match UT1.
The irregularity and unpredictability of UTC leap seconds is problematic for several areas, especially computing (see below). With increasing requirements for accuracy in automation systems and high-speed trading, this raises a number of issues, since a leap second represents a jump as much as a million times larger than the accuracy required for industry clocks.[citation needed] Consequently, the long-standing practice of inserting leap seconds is under review by the relevant international standards body.
International proposals for elimination of leap seconds[edit]
On July 5, 2005, the Head of the Earth Orientation Center of the IERS sent a notice to IERS Bulletins C and D subscribers, soliciting comments on a U.S. proposal before the ITU-R Study Group 7's WP7-A to eliminate leap seconds from the UTC broadcast standard before 2008 (the ITU-R is responsible for the definition of UTC).[b] It was expected to be considered in November 2005, but the discussion has since been postponed.[25] Under the proposal, leap seconds would be technically replaced by leap hours as an attempt to satisfy the legal requirements of several ITU-R member nations that civil time be astronomically tied to the Sun.
A number of objections to the proposal have been raised. Dr. P. Kenneth Seidelmann, editor of the Explanatory Supplement to the Astronomical Almanac, wrote a letter lamenting the lack of consistent public information about the proposal and adequate justification.[26] Steve Allen of the University of California, Santa Cruz cited what he claimed to be the large impact on astronomers in a Science News article.[27] He has an extensive online site[28] devoted to the issues and the history of leap seconds, including a set of references about the proposal and arguments against it.[29]
At the 2014 General Assembly of the International Union of Radio Scientists (URSI), Dr. Demetrios Matsakis, the United States Naval Observatory's Chief Scientist for Time Services, presented the reasoning in favor of the redefinition and rebuttals to the arguments made against it.[30] He stressed the practical inability of software programmers to allow for the fact that leap seconds make time appear to go backwards, particularly when most of them do not even know that leap seconds exist. The possibility of leap seconds being a hazard to navigation was presented, as well as the observed effects on commerce.
The United States formulated its position on this matter based upon the advice of the National Telecommunications and Information Administration[31] and the Federal Communications Commission (FCC), which solicited comments from the general public.[32] This position is in favor of the redefinition.[33][c]
In 2011, Chunhao Han of the Beijing Global Information Center of Application and Exploration said China had not decided what its vote would be in January 2012, but some Chinese scholars consider it important to maintain a link between civil and astronomical time due to Chinese tradition. The 2012 vote was ultimately deferred.[35] At an ITU/BIPM-sponsored workshop on the leap second, Dr. Han expressed his personal view in favor of abolishing the leap second,[36] and similar support for the redefinition was again expressed by Dr. Han, along with other Chinese timekeeping scientists, at the URSI General Assembly in 2014.
At a special session of the Asia-Pacific Telecommunity Meeting on February 10, 2015, Chunhao Han indicated China was now supporting the elimination of future leap seconds, as were all the other presenting national representatives (from Australia, Japan, and the Republic of Korea). At this meeting, Bruce Warrington (NMI, Australia) and Tsukasa Iwama (NICT, Japan) indicated particular concern for the financial markets due to the leap second occurring in the middle of a workday in their part of the world.[d] Subsequent to the CPM15-2 meeting in March/April 2015 the draft gives four methods which the WRC-15 might use to satisfy Resolution 653 from WRC-12.[39]
Arguments against the proposal include the unknown expense of such a major change and the fact that universal time will no longer correspond to mean solar time. It is also answered that two timescales that do not follow leap seconds are already available, International Atomic Time (TAI) and Global Positioning System (GPS) time. Computers, for example, could use these and convert to UTC or local civil time as necessary for output. Inexpensive GPS timing receivers are readily available, and the satellite broadcasts include the necessary information to convert GPS time to UTC. It is also easy to convert GPS time to TAI, as TAI is always exactly 19 seconds ahead of GPS time. Examples of systems based on GPS time include the CDMA digital cellular systems IS-95 and CDMA2000. In general, computer systems use UTC and synchronize their clocks using Network Time Protocol (NTP). Systems that cannot tolerate disruptions caused by leap seconds can base their time on TAI and use Precision Time Protocol. However, the BIPM has pointed out that this proliferation of timescales leads to confusion.[40]
At the 47th meeting of the Civil Global Positioning System Service Interface Committee in Fort Worth, Texas in September 2007, it was announced that a mailed vote would go out on stopping leap seconds. The plan for the vote was:[41]
- April 2008: ITU Working Party 7A will submit to ITU Study Group 7 project recommendation on stopping leap seconds
- During 2008, Study Group 7 will conduct a vote through mail among member states
- October 2011: The ITU-R released its status paper, Status of Coordinated Universal Time (UTC) study in ITU-R, in preparation for the January 2012 meeting in Geneva; the paper reported that, to date, in response to the UN agency's 2010 and 2011 web based surveys requesting input on the topic, it had received 16 responses from the 192 Member States with "13 being in favor of change, 3 being contrary."[42]
- January 2012: The ITU makes a decision.
In January 2012, rather than decide yes or no per this plan, the ITU decided to postpone a decision on leap seconds to the World Radiocommunication Conference in November 2015. At this conference, it was again decided to continue using leap seconds, pending further study and consideration at the next conference in 2023.[43]
In October 2014, Dr. Włodzimierz Lewandowski, chair of the timing subcommittee of the Civil GPS Interface Service Committee and a member of the ESA Navigation Program Board, presented a CGSIC-endorsed resolution to the ITU that supported the redefinition and described leap seconds as a "hazard to navigation".[44]
Some of the objections to the proposed change have been answered by its opponents. For example, Dr. Felicitas Arias, who, as Director of the International Bureau of Weights and Measures (BIPM)'s Time, Frequency, and Gravimetry Department, is responsible for generating UTC, noted in a press release that the drift of about one minute every 60–90 years could be compared to the 16-minute annual variation between true solar time and mean solar time, the one hour offset by use of daylight time, and the several-hours offset in certain geographically extra-large time zones.[45]
Issues created by insertion (or removal) of leap seconds[edit]
Calculation of time differences and sequence of events[edit]
To compute the elapsed time in seconds between two given UTC dates requires the consultation of a table of leap seconds, which needs to be updated whenever a new leap second is announced. Since leap seconds are known only 6 months in advance, time intervals for UTC dates farther in the future cannot be computed.
Missing leap seconds announcement[edit]
Although BIPM announces a leap second 6 months in advance, most time distribution systems (SNTP, IRIG-B, PTP) announce leap seconds at most 12 hours in advance,[citation needed] sometimes only in the last minute and some even not at all (DNP 03).[citation needed] Clocks that are not regularly synchronized can miss a leap second, but still can claim to be perfectly synchronized.[clarification needed]
Implementation differences[edit]
Not all clocks implement leap seconds in the same manner. Leap seconds in Unix time are commonly implemented by repeating 23:59:59 or adding 23:59:60. Network Time Protocol (SNTP) freezes time during the leap second,[citation needed] some time servers declare "alarm condition".[citation needed] Other schemes smear time in the vicinity of a leap second.[46][47]
Binary representation of the leap second[edit]
While the textual representation of leap seconds is defined by BIPM as "23:59:60", most computer operating systems and most time distribution systems derive this human-readable text from a binary counter indicating the number of seconds elapsed since an arbitrary epoch; for instance, since 1970-01-01 00:00:00 in Unix machines or since 1900-01-01 00:00:00 in NTP. This counter has no indicator that a leap second has been inserted, therefore two seconds in sequence will have the same counter value. Some computer operating systems, in particular Linux, assign to the leap second the counter value of the preceding, 23:59:59 second (59-59-0 sequence), while other computers (and the IRIG-B time distribution) assign to the leap second the counter value of the next, 00:00:00 second (59-0-0 sequence).[citation needed] Since there is no standard governing this sequence, the time stamp of values sampled at exactly the same time can vary by one second. This may explain flaws in time-critical systems that rely on time-stamped values.[citation needed]
Textual representation of the leap second[edit]
The textual representation is not always accepted. Entering "2016-12-31 23:59:60" in a POSIX converter will fail and XML will reject such entry as "invalid time". This can cause an exception status in application programs.
Other reported software problems associated with the leap second[edit]
A number of organizations reported problems caused by flawed software following the June 30, 2012, leap second. Among the sites which reported problems were Reddit (Apache Cassandra), Mozilla (Hadoop),[48]Qantas,[49] and various sites running Linux.[50]
Older versions of Motorola Oncore VP, UT, GT, and M12 GPS receivers had a software bug that would cause a single timestamp to be off by a day if no leap second was scheduled for 256 weeks. On November 28, 2003, this happened. At midnight, the receivers with this firmware reported November 29, 2003 for one second and then reverted to November 28, 2003.[51][52]
Older Trimble GPS receivers had a software flaw that would insert a leap second immediately after the GPS constellation started broadcasting the next leap second insertion time (some months in advance of the actual leap second), rather than waiting for the next leap second to happen. This left the receiver's time off by a second in the interim.[53][54]
Older Datum Tymeserve 2100 GPS receivers and Symmetricom Tymeserve 2100 receivers also have a similar flaw to that of the older Trimble GPS receivers, with the time being off by one second. The advance announcement of the leap second is applied as soon as the message is received, instead of waiting for the correct date. A workaround has been described and tested, but if the GPS system rebroadcasts the announcement, or the unit is powered off, the problem will occur again.[55]
On January 21, 2015, several models of GPS receivers implemented the leap second as soon as the announcement was broadcast by GPS, instead of waiting until the implementation date of June 30.[56]
The NTP protocol specifies a flag to inform the receiver that a leap second is imminent. However, some NTP servers have failed to set their leap second flag correctly.[57][58][59][60] Some NTP servers have responded with the wrong time for up to a day after a leap second insertion.[61]
Four different brands of marketed navigational receivers that use data from GPS or Galileo along with the Chinese BeiDou satellites, and even some receivers that use BeiDou satellites alone, were found to implement leap seconds one day early.[62] This was traced to the fact that BeiDou numbers the days of the week from 0 to 6, while GPS and Galileo number them from 1 to 7.
The effect of leap seconds on the commercial sector has been described as "a nightmare".[63] Because financial markets are vulnerable to both technical and legal leap second problems, the Intercontinental Exchange, parent body to 7 clearing houses and 11 stock exchanges including the New York Stock Exchange, ceased operations for 61 minutes at the time of the June 30, 2015 leap second.[64]
Despite the publicity given to the 2015 leap second, a small number of network failures occurred due to leap second-related software errors of some routers.[65] Also, interruptions of around 40 minutes' duration occurred with Twitter, Instagram, Pinterest, Netflix, Amazon, and Apple's music streaming series Beats 1.[66]
Several older versions of the Cisco Systems NEXUS 5000 Series Operating System NX-OS (versions 5.0, 5.1, 5.2) are affected by leap second bugs.[67]
Leap second software bugs have affected the Altea airlines reservation system used by Qantas and Virgin Australia.[68]
Cloudflare was affected by a leap second software bug. Its DNS resolver implementation incorrectly calculated a negative number when subtracting two timestamps obtained from the Go programming language's function, which then used only a real-time clock source.[69] This could have been avoided by using a monotonic clock source, which has since been added to Go 1.9.[70]
There were misplaced concerns that farming equipment using GPS during harvests occurring on December 31, 2016, would be affected by the 2016 leap second.[71] GPS navigation makes use of GPS time, which is not impacted by the leap second.[72]
Workarounds for leap second problems[edit]
The most obvious workaround is to use the TAI scale for all operational purposes and convert to UTC for human-readable text. UTC can always be derived from TAI with a suitable table of leap seconds; the reverse is unsure. The Society of Motion Picture and Television Engineers (SMPTE) video/audio industry standards body selected TAI for deriving time stamps of media.[73] IEC/IEEE 60802 (Time sensitive networks) specifies TAI for all operations. Grid automation is planning to switch to TAI for global distribution of events in electrical grids. Bluetooth mesh networking also uses TAI.[74]
Instead of inserting a leap second at the end of the day, Google servers implement a "leap smear", extending seconds slightly over a 24-hour period centered on the leap second.[47] Amazon followed a similar, but slightly different, pattern for the introduction of the June 30, 2015 leap second,[75] leading to another case of the proliferation of timescales. They later released an NTP service for EC2 instances which performs leap smearing.[76] UTC-SLS was proposed as a version of UTC with linear leap smearing, but it never became standard.[77]
It has been proposed that media clients using the Real-time Transport Protocol inhibit generation or use of NTP timestamps during the leap second and the second preceding it.[78]
NIST has established a special NTP time server to deliver UT1 instead of UTC.[79] Such a server would be particularly useful in the event the ITU resolution passes and leap seconds are no longer inserted.[80] Those astronomical observatories and other users that require UT1 could run off UT1 – although in many cases these users already download UT1-UTC from the IERS, and apply corrections in software.[81]
See also[edit]
- Clock drift, phenomenon where a clock gains or loses time compared to another clock
- DUT1, which describes the difference between coordinated universal time (UTC) and universal time (UT1)
- Dynamical time scale
- Leap year, a year containing one extra day or month
Notes[edit]
- ^Only the Gregorian calendar's leap days begin after February 28. The leap days of other calendars begin at different local times in their own years (Ethiopian calendar, Iranian calendars, Indian national calendar, etc.).
- ^The Wall Street Journal noted that the proposal was considered by a U.S. official at the time to be a "private matter internal to the ITU."[24]
- ^The FCC has posted its received comments, which can be found using their search engine for proceeding 04–286 and limiting the "received period" to those between January 27 and February 18, 2014 inclusive.[34]
- ^In addition to publishing the video of the special session,[37] the Australian Communications and Media Authority has a transcript of that session and a web page with draft content of the Conference Preparatory Meeting report and solutions for ITU-R WRC-15 Agenda Item 1.14.[38]
References[edit]
- ^"IERS science background". Frankfurt am Main: IERS. 2013. Archived from the original on August 29, 2016. Retrieved August 6, 2016.
- ^Gambis, Danie (January 5, 2015). "Bulletin C 49". Paris: IERS. Archived from the original on May 30, 2015. Retrieved January 5, 2015.
- ^James Vincent (January 7, 2015). "2015 is getting an extra second and that's a bit of a problem for the internet". The Verge. Archived from the original on March 17, 2017.
- ^Ptolemy; G. J. Toomer (1998). Ptolemy's Alemagest. Toomer, G. J. Princeton, New Jersey: Princeton University Press. pp. 6–7, 23, 211–216. ISBN .
- ^al-Biruni (1879). The chronology of ancient nations: an English version of the Arabic text of the Athâr-ul-Bâkiya of Albîrûnî, or "Vestiges of the Past". Sachau, C. Edward. Oriental Translation Fund of Great Britain & Ireland. pp. 141–149, 158, 408, 410. Archived from the original on November 14, 2017. Used for mean new moons, both in Hebrew calendar cycles and in equivalent astronomical cycles.
- ^Everett, J. D. (1875). Illustrations of the centimetre-gramme-second (C.G.S.) system of units. Taylor and Francis. p. 83.
- ^Pearce, J. A. (1928). "The Variability of the Rotation of the Earth". Journal of the Royal Astronomical Society of Canada. 22: 145–147. Bibcode:1928JRASC..22..145P.
- ^Seidelmann, P. Kenneth, ed. (1992). Explanatory Supplement to the Astronomical Almanac. Mill Valley, California: University Science Books. pp. 79–80. ISBN . Archived from the original on November 14, 2017.
- ^ ab"Leap Seconds". Time Service Department, United States Naval Observatory. Archived from the original on February 7, 2012. Retrieved December 27, 2008.
- ^Wm Markowitz (1988) 'Comparisons of ET (Solar), ET (Lunar), UT and TDT', in (eds.) A K Babcock & G A Wilkins, 'The Earth's Rotation and Reference Frames for Geodesy and Geophysics', IAU Symposia #128 (1988), at pp 413–418.
- ^DD McCarthy and AK Babcock (1986), "The Length of the Day Since 1658", Phys. Earth Planet Inter., No. 44, pp. 281–292
- ^RA Nelson, DD McCarthy, S Malys, J Levine, B Guinot, HF Fliegel, RL Beard, and TR Bartholomew, (2001) "The Leap Second: its History and Possible Future" (2001), Metrologia 38, pp. 509–529
- ^ abcdStephenson, F.R.; Morrison, L.V. (1995). "Long-term fluctuations in the Earth's rotation: 700 BC to AD 1990". Philosophical Transactions of the Royal Society of London A. 351 (1695): 165–202. Bibcode:1995RSPTA.351..165S. doi:10.1098/rsta.1995.0028.
- ^McCarthy, D D; Hackman, C; Nelson, R A (2008). "The Physical Basis of the Leap Second". Astronomical Journal. 136 (5): 1906–1908. Bibcode:2008AJ....136.1906M. doi:10.1088/0004-6256/136/5/1906.
- ^Jespersen, James; Fitz-Randolph, Jane (1999). From Sundials To Atomic Clocks: Understanding Time and Frequency(PDF). National Institute of Standards and Technology. p. 109.
- ^ abBlair, Byron E., ed. (May 1974), NBS Monograph 140: Time and Frequency: Theory and Fundamentals(PDF), p. 8
- ^McCarthy, Dennis D.; Seidelmann, P. Kenneth. Time: From Earth Rotation to Atomic Physics (second ed.).
- ^"IETF Leap Seconds List". Retrieved June 29, 2020.
- ^Gambis, Daniel (July 4, 2008). "Bulletin C 36". Paris: IERS EOP PC, Observatoire de Paris. Archived from the original on October 6, 2009. Retrieved April 18, 2010.
- ^Andrea Thompson (December 8, 2008). "2008 Will Be Just a Second Longer". Live Science. Archived from the original on December 12, 2008. Retrieved December 29, 2008.
- ^"International Telecommunications Union Radiocommunications sector recommendation TF.460-6: Standard-frequency and time-signal emissions". Archived from the original on October 17, 2016. Retrieved February 9, 2017.
- ^Steve Allen (June 8, 2011). "Extrapolations of the difference (TI – UT1)". ucolick.org. Archived from the original on March 4, 2016. Retrieved February 29, 2016.
- ^Cook-Anderson, Gretchen; Beasley, Dolores (January 10, 2005). "NASA Details Earthquake Effects on the Earth". National Aeronautics and Space Administration (press release). Archived from the original on January 27, 2011.
- ^"Why the U.S. Wants To End the Link Between Time and Sun". The Wall Street Journal. Archived from the original on November 7, 2017. Retrieved October 31, 2017.
- ^"Leap second talks are postponed". BBC News. Archived from the original on November 7, 2017. Retrieved October 31, 2017.
- ^Kenneth Seidelmann. "UTC redefinition or change". Archived from the original on January 10, 2006.
- ^Cowen, Ron. (April 22, 2006). "To Leap or Not to Leap: Scientists debate a timely issue". Science News. Archived from the original on May 2, 2006. Retrieved May 19, 2006.
- ^Steve Allen. "UTC might be redefined without Leap Seconds". Archived from the original on June 3, 2017. Retrieved October 31, 2017.
- ^"nc1985wp7a Proposed US Contribution to ITU-R WP 7A". Archived from the original on January 1, 2017. Retrieved October 31, 2017.
- ^Demetrios Matsakis (August 18, 2014). "Comments on the Debate over the Proposal to Redefine UTC"(PDF). Archived(PDF)
What’s New in the PC Atomic Sync 1.7 serial key or number?
Screen Shot

System Requirements for PC Atomic Sync 1.7 serial key or number
- First, download the PC Atomic Sync 1.7 serial key or number
-
You can download its setup from given links:

PC Atomic Sync 1.7 serial key or number & PC Free Download

PC Atomic Sync 1.7 serial key or number& Kali Software Crack
