
JetBrains PyCharm v1.5.2 serial key or number

JetBrains PyCharm v1.5.2 serial key or number
2.1.2. Importing Maven Modules
Let’s load in some actual code! We do this by importing the Maven modules.
First up, open up the Maven tool window (). You can then use the 'plus' button to add Maven modules. In the screenshot you can see we’ve loaded in Apache Isis core; the modules are listed in the Maven Projects window and corresponding (IntelliJ) modules are shown in the Projects window:

We can then import another module (from some other directory). For example, here we are importing the Isis Addons' todoapp example:

You should then see the new Maven module loaded in the Projects window and also the Maven Projects window:

If any dependencies are already loaded in the project, then IntelliJ will automatically update the CLASSPATH to resolve to locally held modules (rather from folder). So, for example (assuming that the is correct, of course), the Isis todoapp will have local dependencies on the Apache Isis core.
You can press F4 (or use ) to see the resolved classpath for any of the modules loaded into the project.
If you want to focus on one set of code (eg the Isis todoapp but not Apache Isis core) then you could remove the module; but better is to ignore those modules. This will remove from the the Projects window but keep them available in the Maven Projects window for when you next want to work on them:
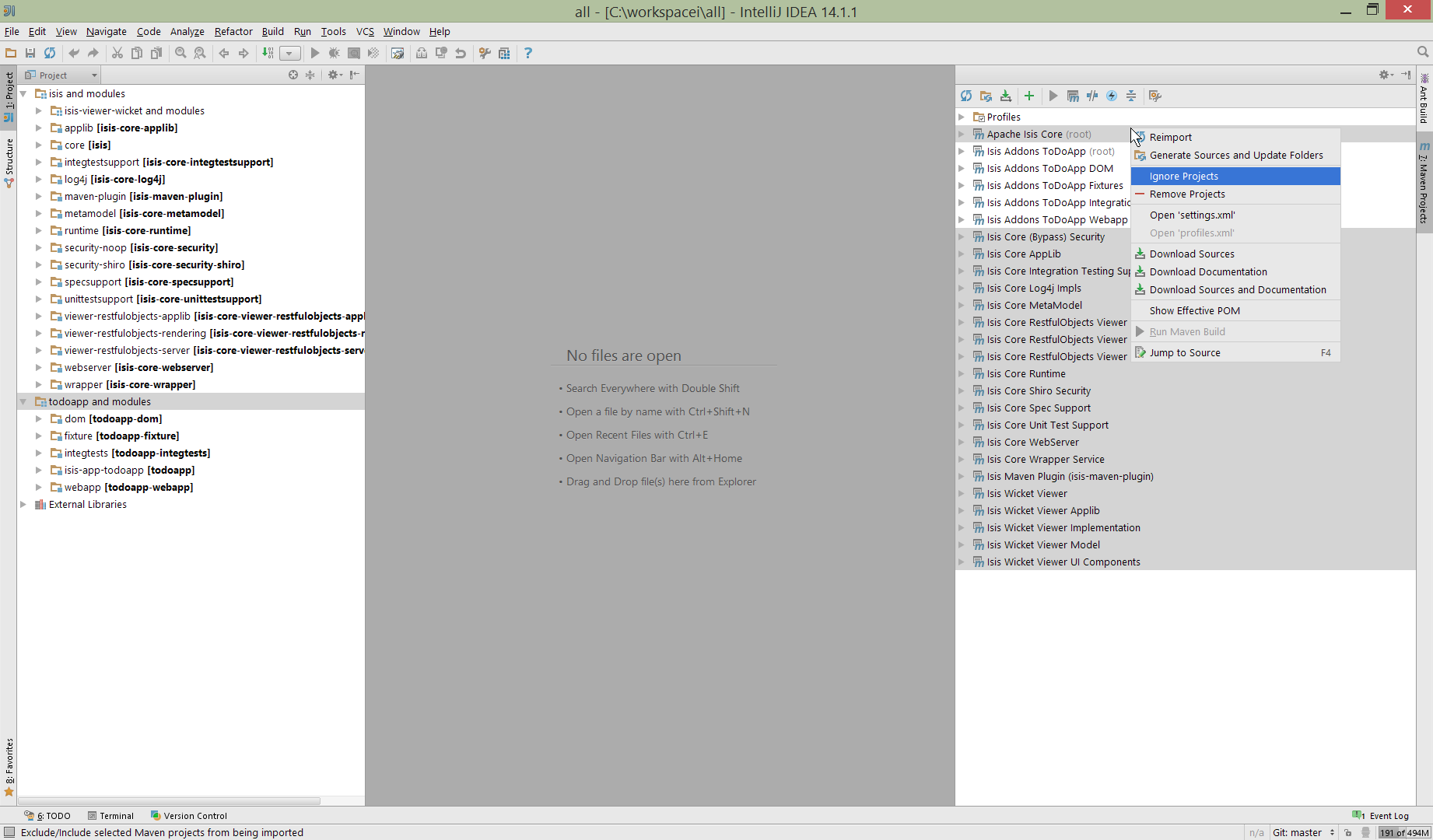
Confirm that it’s ok to ignore these modules:

All being well you should see that the Projects window now only contains the code you are working on. Its classpath dependencies will be adjusted (eg to resolve to Apache Isis core from ):

2.1.3. Running
Let’s see how to run both the app and the tests.
Running the App
Once you’ve imported your Isis application, we should run it. We do this by creating a Run configuration, using .
Set up the details as follows:

We specify the to be ; this is a wrapper around Jetty. It’s possible to pass program arguments to this (eg to automatically install fixtures), but for now leave this blank.
Also note that is the webapp module for your app, and that the is .
Next, and most importantly, configure the DataNucleus enhancer to run for your goal. This can be done by defining a Maven goal to run before the app:

The flag in the goal means run off-line; this will run faster.
| if you forget to set up the enhancer goal, or don’t run it on the correct (dom) module, then you will get all sorts of errors when you startup. These usually manifest themselves as class cast exception in DataNucleus. |
You should now be able to run the app using . The same configuration can also be used to debug the app if you so need.
Running the Unit Tests
The easiest way to run the unit tests is just to right click on the module in the Project Window, and choose run unit tests. Hopefully your tests will pass (!).

As a side-effect, this will create a run configuration, very similar to the one we manually created for the main app:

Thereafter, you should run units by selecting this configuration (if you use the right click approach you’ll end up with lots of run configurations, all similar).
Running the Integration Tests
Integration tests can be run in the same way as unit tests, however the module must also have been enhanced.
One approach is to initially run the tests use the right click on the module; the tests will fail because the code won’t have been enhanced, but we can then go and update the run configuration to run the datanucleus enhancer goal (same as when running the application):

2.1.4. Hints and Tips
Keyboard Cheat Sheets
You can download 1-page PDFs cheat sheets for IntelliJ’s keyboard shortcuts: * for Windows * for MacOS
Probably the most important shortcut on them is for : - on Windows - on MacOS.
This will let you search for any action just by typing its name.
Switch between Tools & Editors
The Tool Windows are the views around the editor (to left, bottom and right). It’s possible to move these around to your preferred locations.
Use through (or through ) to select the tool windows
Press it twice and the tool window will hide itself; so can use to toggle
If in the Project Window (say) and hit enter on a file, then it will be shown in the editor, but (conveniently) the focus remains in the tool window. To switch to the editor, just press .
If in the Terminal Window, you’ll need to press .
If on the editor and want to locate the file in (say) the Project Window, use .
To change the size of any tool window, use
Using these shortcuts you can easily toggle between the tool windows and the editor, without using the mouse. Peachy!
Navigating Around
For all of the following, you don’t need to type every letter, typing "ab" will actually search for ".a.*b.".
to open classes or files or methods that you know the name of:
to open class
to open a file
(bit fiddly this) to search for any symbol.
open up dialog of recent files:
search for any file:
Navigating around: * find callers of a method (the call hierarchy): * find subclasses or overrides: * find superclasses/interface/declaration:
Viewing the structure (ie outline) of a class * will pop-up a dialog showing all members ** hit again to also see inherited members
Editing
Extend selection using
and contract it down again using
to duplicate a line, it’s
if you have some text selected (or even some lines), it’ll actually duplicate the entire selection
to delete a line, it’s
to move a line up or down: and
if you have selected several lines, it’ll move them all togethe
can be handy for joining lines together
just hit enter to split them apart (even in string quotes; IntelliJ will "do the right thing")
Intentions and Code Completion
Massively useful is the "Intentions" popup; IntelliJ tries to guess what you might want to do. You can activate this using`alt-enter`, whenever you see a lightbulb/tooltip in the margin of the current line.
Code completion usually happens whenever you type '.'. You can also use to bring these up.
In certain circumstances (eg in methods0) you can also type to get a smart list of methods etc that you might want to call. Can be useful.
Last, when invoking a method, use to see the parameter types.
Refactoring
Loads of good stuff on the menu; most used are:
Rename ()
Extract
method:
variable:
Inline method/variable:
Change signature
If you can’t remember all those shortcuts, just use (might want to rebind that to something else!) and get a context-sensitive list of refactorings available for the currently selected object
Plugins
You might want to set up some additional plugins. You can do this using (or equivalently ).
Some others you might like to explore are:

Maven Helper Plugin
This plugin provides a couple of great features. One is better visualization of dependency trees (similar to Eclipse).
If you open a file, you’ll see an additional "Dependencies" tab:

Clicking on this gives a graphical tree representation of the dependencies, similar to that obtained by , but filterable.

The plugin also provides the ability to easily run a Maven goal on a project:

This menu can also be bound to a keystroke so that it is available as a pop-up:

Troubleshooting
When a Maven module is imported, IntelliJ generates its own project files (suffix ), and the application is actually built from that.
Occasionally these don’t keep in sync (even if auto-import of Maven modules has been enabled).
To fix the issue, try: * reimport module * rebuild selected modules/entire project * remove and then re-add the project * restart, invalidating caches * hit StackOverflow (!)
One thing worth knowing; IntelliJ actively scans the filesystem all the time. It’s therefore (almost always) fine to build the app from the Maven command line; IntelliJ will detect the changes and keep in sync. If you want to force that, use , .
If you hit an error of "duplicate classes":

then make sure you have correctly configured the annotation processor settings. Pay attention in particular to the "Production sources directory" and "Test sources directory", that these are set up correctly.
2.1.5. Running Integration Tests
When running integration tests from within IntelliJ, make sure that the radio button is set to :

If this radio button is set to one of the other options then you may obtain class loading issues; these result from IntelliJ attempting to run unit tests of the project that depend on test classes in that module, but using the classpath of the module whereby the test-classes ( artifact) are not exposed on the Maven classpath.
2.1.6. Advanced
In this section are a couple of options that will reduce the length of the change code/build/deploy/review feedback loop.
Setting up Dynamic Reloading
DCEVM enhances the JVM with true hot-swap adding/removing of methods as well as more reliable hot swapping of the implementation of existing methods.
In the context of Apache Isis, this is very useful for contributed actions and mixins and also view models; you should then be able to write these actions and have them be picked up without restarting the application.
Changing persisting domain entities is more problematic, for two reasons: the JDO/DataNucleus enhancer needs to run on domain entities, and also at runtime JDO/DataNucleus would need to rebuild its own metamodel. You may find that adding actions will work, but adding new properties or collections is much less likely to.
To set up DCEVM, download the appropriate JAR from the github page, and run the installer. For example:
Be sure to run with appropriate privileges to be able to write to the installation directories of the JDK. If running on Windows, that means running as . |
After a few seconds this will display a dialog listing all installations of JDK that have been found:

Select the corresponding installation, and select .

In IntelliJ, register the JDK in dialog:

Finally, in the run configuration, select the patched JDK:

Setting up JRebel
See the repo for the (non-ASF) Isis JRebel plugin. With some modification, this should work for IntelliJ too.
Note that JRebel is a commercial product, requiring a license. At the time of writing there is also currently a non-commercial free license (though note this comes with some usage conditions).
About MariaDB Connector/J
MariaDB Connector/J is used to connect applications developed in Java to MariaDB and MySQL databases using the standard JDBC API. The library is LGPL licensed.
About MariaDB Connector/J
MariaDB Connector/J is a Type 4 JDBC driver. It was developed specifically as a lightweight JDBC connector for use with MariaDB and MySQL database servers. It was originally based on the Drizzle JDBC code with numerous additions and bug fixes.
Server Compatibility
MariaDB Connector/J is compatible with all MariaDB and MySQL server versions 5.5.3 and later.
MariaDB Connector/J releases older than 1.2.0 may be compatible with server versions older than MariaDB 5.5 and MySQL 5.5, but those MariaDB Connector/J releases aren't supported anymore.
Java Compatibility
To determine which MariaDB Connector/J release series would be best to use for each Java version, please see the following table:
| Java Version(s) | Recommended MariaDB Connector/J Release Series | JDBC Version |
|---|---|---|
| Java 11, Java 8 | MariaDB Connector/J 2.6 | JDBC 4.2 |
| Java 7 | MariaDB Connector/J 1.8 | JDBC 4.1 |
To determine which Java versions each MariaDB Connector/J release series supports, please see the following table:
| MariaDB Connector/J Release Series | Supported Java Version(s) |
|---|---|
| MariaDB Connector/J 2.0 and above | Java 11, Java 8 |
| MariaDB Connector/J 1.6 to 1.8 | Java 11, Java 8, Java 7 |
Installing MariaDB Connector/J
MariaDB Connector/J can be installed using Maven, Gradle, or by manually putting the file in your . See Installing MariaDB Connector/J for more information.
MariaDB Connector/J files and source code tarballs can be downloaded from the following URL:
MariaDB Connector/J files can also be downloaded from the following URL:
Installing Dependencies
JNA (net.java.dev.jna:jna) and JNA-PLATFORM (net.java.dev.jna:jna-platform) 4.2.1 or greater are also needed when you would like to connect to the server with Unix sockets or windows pipes.
Using the Driver
The following subsections show the formatting of JDBC connection strings for MariaDB and MySQL database servers. Additionally, sample code is provided that demonstrates how to connect to one of these servers and create a table.
Getting a New Connection
There are two standard ways to get a connection:
Using DriverManager
The preferred way to get a connection with MariaDB Connector/J is to use the class. When the class is used to locate and load MariaDB Connector/J, the application needs no further configuration. The class will automatically load MariaDB Connector/J and allow it to be used in the same way as any other JDBC driver.
For example:
Connection connection = DriverManager.getConnection("jdbc:mariadb://localhost:3306/DB?user=root&password=myPassword");The legacy way of loading a JDBC driver also still works for MariaDB Connector/J. e.g.:
Having MariaDB and MySQL Drivers in the Same Classpath
MariaDB Connector/J permits connection URLs beginning with both and .
However, if you also have MySQL's JDBC driver in your , then this could cause issues. To permit having MariaDB Connector/J and MySQL's JDBC driver in your at the same time, MariaDB Connector/J 1.5.9 and later do not accept connection URLs beginning with if the option is set in the connection URL.
For example, the following connection URL would not be accepted by MariaDB Connector/J:
jdbc:mysql://localhost:3306/db?user=someUser&disableMariaDbDriverThis allows you to have MariaDB Connector/J and MySQL's JDBC driver in your at the same time.
Using a Pool
Another way to get a connection with MariaDB Connector/J is to use a connection pool.
MariaDB Connector/J provides 2 different Datasource pool implementations:
- : The basic implementation. It creates a new connection each time the method is called.
- : A connection pool implementation. It maintains a pool of connections, and when a new connection is requested, one is borrowed from the pool.
Internal Pool
The driver's internal pool configuration provides a very fast pool implementation and deals with the issues most of the java pool have:
- 2 different connection states cleaning after release
- deals with non-activity (connections in the pool will be released if not used after some time, avoiding the issue created when the server closes the connection after @wait_timeout is reached).
See the pool documentation for more information.
External pool
When using an external connection pool, the MariaDB Driver class must be configured.
Example using hikariCP JDBC connection pool :
final HikariDataSource ds = new HikariDataSource(); ds.setMaximumPoolSize(20); ds.setDriverClassName("org.mariadb.jdbc.Driver"); ds.setJdbcUrl("jdbc:mariadb://localhost:3306/db"); ds.addDataSourceProperty("user", "root"); ds.addDataSourceProperty("password", "myPassword"); ds.setAutoCommit(false);Please note that the driver class provided by MariaDB Connector/J is not but !
The class can be used when the pool datasource configuration only permits the java.sql.Datasource implementation.
Connection Strings
The format of the JDBC connection string is:
jdbc:(mysql|mariadb):[replication:|loadbalance:|sequential:|aurora:]//<hostDescription>[,<hostDescription>...]/[database][?<key1>=<value1>[&<key2>=<value2>]]HostDescription:
<host>[:<portnumber>] or address=(host=<host>)[(port=<portnumber>)][(type=(master|slave))]Some notes about this:
- The host must be a DNS name or IP address.
- If the host is an IPv6 address, then it must be inside square brackets.
- The default port is .
- The default type is .
- If the failover and load-balancing mode is set to , then the connector assumes that the first host is master, and the others are slaves by default, if their types are not explicitly mentioned.
Examples:
Failover and Load-Balancing Modes
Failover and Load-Balancing Modes were introduced in MariaDB Connector/J 1.2.0.
| Mode | Description |
|---|---|
| This mode supports connection failover in a multi-master environment, such as MariaDB Galera Cluster. This mode does not support load-balancing reads on slaves. The connector will try to connect to hosts in the order in which they were declared in the connection URL, so the first available host is used for all queries. For example, let's say that the connection URL is the following: When the connector tries to connect, it will always try host1 first. If that host is not available, then it will try host2. etc. When a host fails, the connector will try to reconnect to hosts in the same order. This mode has been available since MariaDB Connector/J 1.3.0 | |
| This mode supports connection load-balancing in a multi-master environment, such as MariaDB Galera Cluster. This mode does not support load-balancing reads on slaves. The connector performs load-balancing for all queries by randomly picking a host from the connection URL for each connection, so queries will be load-balanced as a result of the connections getting randomly distributed across all hosts. Before 2.4.2, this option was named `failover` - alias still exist for compatibility - . This mode has been available since MariaDB Connector/J 1.2.0 | |
| This mode supports connection failover in a master-slave environment, such as a MariaDB Replication cluster. The mode supports environments with one or more masters. This mode does support load-balancing reads on slaves if the connection is set to read-only before executing the read. The connector performs load-balancing by randomly picking a slave from the connection URL to execute read queries for a connection. This mode has been available since MariaDB Connector/J 1.2.0 | |
| This mode supports connection failover in an Amazon Aurora cluster. This mode does support load-balancing reads on slave instances if the connection is set to read-only before executing the read. The connector performs load-balancing by randomly picking a slave instance to execute read queries for a connection. This mode has been available since MariaDB Connector/J 1.2.0 |
See failover description for more information.
Optional URL Parameters
General remark: Unknown options are accepted and silently ignored.
The following options are currently supported.
Essential Parameters
| Parameter | Description |
|---|---|
| Database user name. since 1.0.0 | |
| Password of database user. since 1.0.0 | |
| For insert queries, rewrite batchedStatement to execute in a single executeQuery. example: with first batch values = 1, second = 2 will be rewritten . If query cannot be rewriten in "multi-values", rewrite will use multi-queries : with values [1,2] and [2,3]" will be rewritten when active, the useServerPrepStmts option is set to false Default: false. Since 1.1.8 | |
| The connect timeout value, in milliseconds, or zero for no timeout. Default: 30 000. Since 1.1.8 | |
| PrepareStatement are prepared on the server side before executing. The applications that repeatedly use the same queries have value to activate this option, but the general case is to use the direct command (text protocol). if rewriteBatchedStatements is set to true, this option will be set to false Default: false (was true before 1.6.0). Since 1.3.0 | |
| *Not compatible with aurora* Driver will can send queries by batch. If set to , queries are sent one by one, waiting for the result before sending the next one. If set to , queries will be sent by batch corresponding to the useBatchMultiSendNumber option value (default 100) or according to the max_allowed_packet server variable if the packet size does not permit sending as many queries. Results will be read later, avoiding a lot of network latency when the client and server aren't on the same host. This option is mainly effective when the client is distant from the server. More information here Default: true (false if using aurora failover) . Since 1.5.0 | |
| Permit loading data from file. see LOAD DATA LOCAL INFILE. Default: false. Since 1.2.1 | |
| databaseMetaData.getDatabaseProductName() return "MariaDB" or "MySQL" according to server type (since 2.4.0). This option permit to force returning "MySQL" even if server is MariaDB to permit compatibility with frameworks that doesn't support MariaDB. Default: false. Since 2.4.1 |
TLS Parameters
more information on Using TLS/SSL with MariaDB java connector
| Parameter | Description |
|---|---|
| Force SSL/TLS on connection. Default: false. Since 1.1.0 | |
| When using SSL/TLS, do not check server's certificate. Default: false. Since 1.1.1 | |
| Permits providing server's certificate in DER form, or server's CA certificate. The server will be added to trustStor. This permits a self-signed certificate to be trusted. Can be used in one of 3 forms : * serverSslCert=/path/to/cert.pem (full path to certificate) * serverSslCert=classpath:relative/cert.pem (relative to current classpath) * or as verbatim DER-encoded certificate string "------BEGIN CERTIFICATE-----" . since 1.1.3 | |
| File path of the keyStore file that contain client private key store and associate certificates (similar to java System property "javax.net.ssl.keyStore", but ensure that only the private key's entries are used).(legacy alias clientCertificateKeyStoreUrl). Since 1.3.4 | |
| Password for the client certificate keyStore (similar to java System property "javax.net.ssl.keyStorePassword").(legacy alias clientCertificateKeyStorePassword) Since 1.3.4 | |
| Password for the private key in client certificate keyStore. (only needed if private key password differ from keyStore password). Since 1.5.3 | |
| File path of the trustStore file (similar to java System property "javax.net.ssl.trustStore"). (legacy alias trustCertificateKeyStoreUrl) Use the specified file for trusted root certificates. When set, overrides serverSslCert. Since 1.3.4 | |
| Password for the trusted root certificate file (similar to java System property "javax.net.ssl.trustStorePassword"). (legacy alias trustCertificateKeyStorePassword). Since 1.3.4 | |
| Force TLS/SSL protocol to a specific set of TLS versions (comma separated list). Example : "TLSv1, TLSv1.1, TLSv1.2" (Alias "enabledSSLProtocolSuites" works too) Default: java default. Since 1.5.0 | |
| Force TLS/SSL cipher (comma separated list). Example : "TLS_DHE_RSA_WITH_AES_256_GCM_SHA384, TLS_DHE_DSS_WITH_AES_256_GCM_SHA384" Default: use JRE ciphers. Since 1.5.0 | |
| When using ssl, the driver checks the hostname against the server's identity as presented in the server's certificate (checking alternative names or the certificate CN) to prevent man-in-the-middle attacks. This option permits deactivating this validation. Hostname verification is disabled when the trustServerCertificate option is set Default: false. Since 2.1.0 | |
| Indicate key store type (JKS/PKCS12). default is null, then using java default type. Since 2.4.0 | |
| Indicate trust store type (JKS/PKCS12). default is null, then using java default type. Since 2.4.0 |
Pool Parameters
See the pool documentation for pool configuration.
| Parameter | Description |
|---|---|
| Use pool. This option is useful only if not using a DataSource object, but only a connection object. Default: false. since 2.2.0 | |
| Pool name that permits identifying threads. default: auto-generated as MariaDb-pool-<pool-index>since 2.2.0 | |
| The maximum number of physical connections that the pool should contain. Default: 8. since 2.2.0 | |
| When connections are removed due to not being used for longer than than "maxIdleTime", connections are closed and removed from the pool. "minPoolSize" indicates the number of physical connections the pool should keep available at all times. Should be less or equal to maxPoolSize. Default: maxPoolSize value. Since 2.2.0 | |
| When asking a connection to pool, the pool will validate the connection state. "poolValidMinDelay" permits disabling this validation if the connection has been borrowed recently avoiding useless verifications in case of frequent reuse of connections. 0 means validation is done each time the connection is asked. Default: 1000 (in milliseconds). Since 2.2.0 | |
| The maximum amount of time in seconds that a connection can stay in the pool when not used. This value must always be below @wait_timeout value - 45s Default: 600 in seconds (=10 minutes), minimum value is 60 seconds. Since 2.2.0 | |
| Indicates the values of the global variables max_allowed_packet, wait_timeout, autocommit, auto_increment_increment, time_zone, system_time_zone and tx_isolation) won't be changed, permitting the pool to create new connections faster. Default: false. Since 2.2.0 | |
| When a connection is closed() (given back to pool), the pool resets the connection state. Setting this option, the prepare command will be deleted, session variables changed will be reset, and user variables will be destroyed when the server permits it (>= MariaDB 10.2.4, >= MySQL 5.7.3), permitting saving memory on the server if the application make extensive use of variables. Must not be used with the useServerPrepStmts option Default: false. Since 2.2.0 | |
| Register JMX monitoring pools. Default: true. Since 2.2.0 |
Log Parameters
| Parameter | Description |
|---|---|
| Enable log information. require Slf4j version > 1.4 dependency. Log level correspond to Slf4j logging implementation Default: false. Since 1.5.0 | |
| Only the first characters corresponding to this options size will be displayed in logs Default: 1024. Since 1.5.0 | |
| Will log query with execution time superior to this value (if defined ) Default: 1024. Since 1.5.0 | |
| log query execution time. Default: false. Since 1.5.0 |
Infrequently Used Parameters
| Parameter | Description |
|---|---|
| Indicate password encoding charset. Charset value must be a Java charset. Example : "UTF-8" Default: null (= platform's default charset) . Since 1.5.9 | |
| Correctly handle subsecond precision in timestamps (feature available with MariaDB 5.3 and later). May confuse 3rd party components (Hibernated). Default: true. Since 1.0.0 | |
| permit multi-queries like . Default: false. Since 1.0.0 | |
| If set to 'true', an exception is thrown during query execution containing a query string. Default: false. Since 1.1.0 | |
| Compresses the exchange with the database through gzip. This permits better performance when the database is not in the same location. Default: false. Since 1.0.0 | |
| to use a custom socket factory, set it to the full name of the class that implements javax.net.SocketFactory. since 1.0.0 | |
| Sets corresponding option on the connection socket. since 1.0.0 | |
| Sets corresponding option on the connection socket. since 1.0.0 | |
| This option can be used in environments where connections are created and closed in rapid succession. Often, it is not possible to create a socket in such an environment after a while, since all local “ephemeral” ports are used up by TCP connections in TCP_WAIT state. Using tcpAbortiveClose works around this problem by resetting TCP connections (abortive or hard close) rather than doing an orderly close. It is accomplished by using socket.setSoLinger(true,0) for abortive close. since 1.1.1 | |
| set buffer size for TCP buffer (SO_RCVBUF). since 1.0.0 | |
| set buffer size for TCP buffer (SO_SNDBUF). since 1.0.0 | |
| On Windows, specify named pipe name to connect to mysqld.exe. since 1.1.3 | |
| Datatype mapping flag, handle MySQL Tiny as BIT(boolean). Default: true. Since 1.0.0 | |
| Year is date type, rather than numerical. Default: true. Since 1.0.0 | |
| <var>=<value> pairs separated by comma, mysql session variables, set upon establishing successful connection. since 1.1.0 | |
| Permits connecting to the database via Unix domain socket, if the server allows it. The value is the path of Unix domain socket (i.e "socket" database parameter : select @@socket) . since 1.1.4 | |
| Permits connecting to the database via shared memory, if the server allows it. The value is the base name of the shared memory. since 1.1.4 | |
| Hostname or IP address to bind the connection socket to a local (UNIX domain) socket. since 1.1.7 | |
| Defined the network socket timeout (SO_TIMEOUT) in milliseconds. Value of 0 disables this timeout. If the goal is to set a timeout for all queries, since MariaDB 10.1.1, the server has permitted a solution to limit the query time by setting a system variable, max_statement_time. The advantage is that the connection then is still usable. Default: 0 (standard configuration) or 10000ms (using "aurora" failover configuration). since 1.1.7 | |
| Session timeout is defined by the wait_timeout server variable. Setting interactiveClient to true will tell the server to use the interactive_timeout server variable. Default: false. Since 1.1.7 | |
| Metadata ResultSetMetaData.getTableName() returns the physical table name. "useOldAliasMetadataBehavior" permits activating the legacy code that sends the table alias if set. Default: false. Since 1.1.9 | |
| the specified database in the url will be created if nonexistent. Default: false. Since 1.1.7 | |
| Defines the server time zone. to use only if the jre server has a different time implementation of the server. (best to have the same server time zone when possible). since 1.1.7 | |
| if useServerPrepStmts = true, cache the prepared informations in a LRU cache to avoid re-preparation of command. Next use of that command, only prepared identifier and parameters (if any) will be sent to server. This mainly permit for server to avoid reparsing query. Default: true. Since 1.3.0 | |
| if useServerPrepStmts = true, defines the prepared statement cache size that option `cachePrepStmts` use. Default: 250. Since 1.3.0 | |
| if useServerPrepStmts = true, defined queries larger than this size will not be cached. Default: 2048. Since 1.3.0 | |
| Truncation error ("Data truncated for column '%' at row %", "Out of range value for column '%' at row %") will be thrown as an error, and not as a warning. Default: true. Since 1.4.0 | |
| enable/disable callable Statement cache Default: true. Since 1.4.0 | |
| This sets the number of callable statements that the driver will cache per VM if "cacheCallableStmts" is enabled. Default: true. Since 1.4.0 | |
| When option useBatchMultiSend is active, indicate the maximum query send in a row before reading results. Default: 100. Since 1.5.0 | |
| When performance_schema is active, permit to send server some client information in a key;value pair format (example: connectionAttributes=key1:value1,key2,value2). Those informations can be retrieved on server within tables performance_schema.session_connect_attrs and performance_schema.session_account_connect_attrs. This can permit from server an identification of client/application Since 1.4.0 | |
| *Not compatible with aurora* During connection, different queries are executed. When option is active those queries are send using pipeline (all queries are send, then only all results are reads), permitting faster connection creation. Default: true. Since 1.6.0 | |
| Driver will save the last 16 MySQL packet exchanges (limited to first 1000 bytes). Hexadecimal value of those packets will be added to stacktrace when an IOException occur. This option has no impact on performance but driver will then take 16kb more memory. Default: false. Since 1.6.0, 2.0.1 | |
| Use dedicated COM_STMT_BULK_EXECUTE protocol for batch insert when possible. (batch without Statement.RETURN_GENERATED_KEYS and streams) to have faster batch. (significant only on >= MariaDB 10.2.7) Default: false. (was true for version >= 2.1.0 & < 2.3.0) | |
| Set default autocommit value on connection initialization Default: true. Since 2.2.0 | |
| Usually, Connection.isValid just send an empty packet to server, and server send a small response to ensure connectivity. When this option is set, connector will ensure Galera server state "wsrep_local_state" correspond to allowed values (separated by comma). example "4,5", recommended is "4". see galera state to know more. Default: empty. Since 2.2.5 | |
| add "SHOW ENGINE INNODB STATUS" result to exception trace when having a deadlock exception. Default: false. Since 2.3.0 | |
| add thread dump to exception trace when having a deadlock exception. Default: false. Since 2.3.0 | |
| Use a buffered inputSteam that read socket available data Default: true. Since 2.4.0 | |
| When using GSSAPI authentication, use this value as the Service Principal Name (SPN) instead of the one defined for the user account on the database server. Since 2.4.0 | |
| force DatabaseMetadata.getDatabaseProductName() to return "MySQL" as database, not real database type. Default: false. Since 2.4.1 | |
| The driver will call setFetchSize(n) with this value on all newly-created Statements. Default: 0. Since 2.4.2 | |
| Resultset metadata getTableName always return blank. This option is mainly for ORACLE db compatibility. Default: false. Since 2.4.3 | |
| Indicate path to RSA server public key file for sha256_password and caching_sha2_password authentication password Since 2.5.0 | |
| Authorize client to retrieve RSA server public key when serverRsaPublicKeyFile is not set (for sha256_password and caching_sha2_password authentication password) Default: false. Since 2.5.0 | |
| Indicate the TLS org.mariadb.jdbc.tls.TlsSocketPlugin plugin type to use. Plugin must be present in classpath Since 2.5.0 | |
| Indicate the credential plugin type to use. Plugin must be present in classpath Since 2.5.0 | |
| Permit to disabled "session_track_schema" setting when server has CLIENT_SESSION_TRACK capability Default: True. Since 2.5.4 |
Failover and Load Balancing Parameters
| Parameter | Description |
|---|---|
| When this parameter enabled when a Failover and Load Balancing Mode is not in use, the connector will simply try to reconnect to its host after a failure. This is referred to as Basic Failover. When this parameter enabled when a Failover and Load Balancing Mode is in use, the connector will blacklist the failed host and try to connect to a different host of the same type. This is referred to as Standard Failover. Default is false. since 1.1.7 | |
| When the connector is performing a failover and all hosts are down, this parameter defines the maximum number of connection attempts the connector will make before throwing an exception. Default: 120 seconds. since 1.2.0 | |
| When the connector is searching silently for a valid host, this parameter defines the maximum number of connection attempts the connector will make before throwing an exception. This parameter differs from the "retriesAllDown" parameter because this silent search is used in situations where the connector can temporarily workaround the problem, such as by using the master connection to execute reads when the slave connection fails. Default: 120. since 1.2.0 | |
| When multiple hosts are configured, the connector verifies that the connections haven't been lost after this much time in seconds has elapsed. When this parameter is set to 0, no verification will be done. Default:120 seconds since 1.2.0 | |
| When a connection fails, this host will be blacklisted for the amount of time defined by this parameter. When connecting to a host, the driver will try to connect to a host in the list of non-blacklisted hosts and, only if none are found, attempt blacklisted ones. This blacklist is shared inside the classloader. Default: 50 seconds. since 1.2.0 | |
| When this parameter enabled when a Failover and Load Balancing Mode is in use, and a read-only connection is made to a host, assure that this connection is in read-only mode by setting the session to read-only. Default to false. Since 1.3.0 | |
| When the Failover and Load Balancing Mode is in use, allow the creation of connections when the master is down. If no masters are available, then the default connection will be a slave, and Connection.isReadOnly() will return true. Default: false. Since 2.2.0 |
JDBC API Implementation Notes
"LOAD DATA INFILE"
The fastest way to load lots of data is using LOAD DATA INFILE.
However, using "LOAD DATA LOCAL INFILE" (ie: loading a file from the client) may be a security problem :
- A "man in the middle" proxy server can change the actual file requested from the server so the client will send a local file to this proxy.
- if someone can execute a query from the client, he can have access to any file on the client (according to the rights of the user running the client process).
A specific option "allowLocalInfile" (default to true) can deactivate functionality on the client side. The global variable local_infile can disable LOAD DATA LOCAL INFILE on the server side.
A non-JDBC method can permit using this kind of query without this security issue: The application has to create an InputStream with the file to load. If MariaDbStatement.setLocalInfileInputStream(InputStream inputStream) is set, the inputStream will be sent to the server, replacing the file content (working even with the "allowLocalInfile" option disabled).
Code example:
Statement statement = ... InputStream in = new FileInputStream("/file.sql"); if (statement.isWrapperFor(MariaDbStatement.class)) { MariaDbStatement mariaDbStatement = statement.unwrap(MariaDbStatement.class); mariaDbStatement.setLocalInfileInputStream(in); String sql = "LOAD DATA LOCAL INFILE 'dummyFileName'" + " INTO TABLE gigantic_load_data_infile " + " FIELDS TERMINATED BY '\\t' ENCLOSED BY ''" + " ESCAPED BY '\\\\' LINES TERMINATED BY '\\n'"; statement.execute(sql); } else { in.close(); throw new RuntimeException("Mariadb JDBC adaptor must be used"); }Since 1.5.0, Interceptors can now filter LOAD DATA LOCAL INFILE queries according to the filename.
These interceptors must implement the interface. Interceptors use the ServiceLoader pattern, so interceptors must be defined in the META-INF/services/org.mariadb.jdbc.LocalInfileInterceptor file.
Example : Create the META-INF/services/org.mariadb.jdbc.LocalInfileInterceptor file with content org.project.LocalInfileInterceptorImpl.
You can avoid defining the META-INF/services file using google auto-service framework Using the previous example, just add , and your interceptor will be automatically defined.
@AutoService(LocalInfileInterceptor.class) public class LocalInfileInterceptorImpl implements LocalInfileInterceptor { @Override public boolean validate(String fileName) { File file = new File(fileName); String absolutePath = file.getAbsolutePath(); String filePath = absolutePath.substring(0,absolutePath.lastIndexOf(File.separator)); return filePath.equals("/var/tmp/exchanges"); } }Set a Query Timeout
Driver follow the JDBC specifications, permitting Statement.setQueryTimeout() for a particular statement.
If the goal is to set a timeout for all queries, since MariaDB 10.1.1, the server permits a limiting query time by setting the system variable max_statement_time.
This solution will handle query timeout better (and faster) than java solutions (JPA2, "javax.persistence.query.timeout", Pools integrated solution like tomcat jdbc-pool "queryTimeout"...).
Option "sessionVariables" permit to set this system variable easily : Example :
#will set a maximum query timeout of 10 seconds for this connection jdbc:mariadb://localhost/db?user=user&sessionVariables=max_statement_time=10Streaming Result Sets
By default, will read the full result set from the server. With large result sets, this will require large amounts of memory.
To avoid using too much memory, rather use Statement.setFetchSize(int numberOfRowInMemory) to indicate the number of rows that will be stored in memory
Example :
using indicates that 1000 rows will be stored in memory.
So, when the query has executed, 1000 rows will be in memory. After 1000 , the next 1000 rows will be stored in memory, and so on.
Note that the server usually expects clients to read off the result set relatively quickly. The net_write_timeout server variable controls this behavior (defaults to 60s). If you don't expect results to be handled in this amount of time there is a different possibility:
- With >= MariaDB 10.1.2, you can use the query "SET STATEMENT net_write_timeout=10000 FOR XXX" with XXX your "normal" query. This will indicate that specifically for this query, net_write_timeout will be set to a longer time (10000 in this example).
- for older servers, a specific query will have to temporarily set net_write_timeout ("SET STATEMENT net_write_timeout=..."), and set it back afterward.
- if your application usually uses a lot of long queries with fetch size, the connection can be set using option "sessionVariables=net_write_timeout=xxx"
Even using setFetchSize, the server will send all results to the client.
If another query is executed on the same connection when a streaming resultset has not been fully read, the connector will put the whole remaining streaming resultset in memory in order to execute the next query. This can lead to OutOfMemoryError if not handled.
Before version 1.4.0, the only accepted value for fetch size was (equivalent to ). This value is still accepted for compatilibity reasons but rather use , since according to JDBC the value must be >= 0.
Prepared Statements
The driver uses server prepared statements as a standard to communicate with the database (since 1.3.0). If the "allowMultiQueries" or "rewriteBatchedStatements" options are set to true, the driver will only use text protocol. Prepared statements (parameter substitution) is handled by the driver, on the client side.
CallableStatement
Callable statement implementation won't need to access stored procedure metadata (mysql.proc) table if both of following are true
- CallableStatement.getMetadata() is not used
- Parameters are accessed by index, not by name
When possible, following the two rules above provides both better speed and eliminates concerns about SELECT privileges on the mysql.proc table.
Optional JDBC Classes
The following optional interfaces are implemented by the org.mariadb.jdbc.MariaDbDataSource class : javax.sql.DataSource, javax.sql.ConnectionPoolDataSource, javax.sql.XADataSource
careful : org.mariadb.jdbc.MySQLDataSource doesn't exist anymore and should be replaced with org.mariadb.jdbc.MariaDbDataSource since v1.3.0
Usage Examples
The following code provides a basic example of how to connect to a MariaDB or MySQL server and create a table.
Creating a Table on a MariaDB or MySQL Server
Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/test", "username", "password"); Statement stmt = connection.createStatement(); stmt.executeUpdate("CREATE TABLE a (id int not null primary key, value varchar(20))"); stmt.close(); connection.close();Services
The driver implements 3 kinds of services:
- Credential service: permit giving credential
- Authentication service: permit adding client authentication plugins.
- SSL factory service: custom TSL implementation
Credential service
Credentials are usually set using user/password in the connection string or by using DriverManager.getConnection(String url, String user, String password).
Credential plugins permit to provide credential information from other means. Those plugins have to be activated setting option `credentialType` to designated plugin.
The driver has 3 default plugins :
AWS IAM
This permits AWS database IAM authentication. The plugin generate a token using IAM credential and region. Token is valid for 15 minutes and cached for 10 minutes.
To use this credential authentication, com.amazonaws:aws-java-sdk-rds dependency must be registred in classpath. Implementation use SDK DefaultAWSCredentialsProviderChain and DefaultAwsRegionProviderChain to get IAM credential and region. see DefaultAWSCredentialsProviderChain and DefaultAwsRegionProviderChain to check how those information can be retrieved (environment variable / system properties, files, ...)
Example:
with AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY and AWS_REGION environment variable set.
Environment
User and Password are retrieved from environment variables. default environment variables are MARIADB_USER and MARIADB_PWD, but can be changed by setting additional option `userKey` and `pwdKey`
Example : using connection string user and password will be retrieved from environment variable MARIADB_USER and MARIADB_PWD.
Property
User and Password are retrieved from java properties. default property name are mariadb.user and mariadb.pwd, but property names can be changed by setting additional option `userKey` and `pwdKey`
Example : using connection string user and password will be retrieved from java properties `mariadbUser` and `mariadbPwd`
Authentication service
Client authentication plugins are now defined as services. This permits to easily add new client authentication plugins.
List of authentication plugins in java connector :
- mysql_clear_password
- auth_gssapi_client
- client_ed25519
- mysql_native_password
- mysql_old_password
- dialog (PAM)
- sha256_password
- caching_sha2_password
New authentication plugins can be created implementing interface org.mariadb.jdbc.authentication.AuthenticationPlugin, and listing new plugin in a META-INF/services/org.mariadb.jdbc.authentication.AuthenticationPlugin file.
SSL factory service
Custom SSL implementation can be used implementing A connection to a server initially creates a socket. When set, SSL socket is layered over this existing socket. Implementing org.mariadb.jdbc.tls.TlsSocketPlugin permit to provide custom SSL implementation for example create a new HostnameVerifier implementation.
Custom implementation need to implement org.mariadb.jdbc.tls.TlsSocketPlugin and register service META-INF/services/org.mariadb.jdbc.tls.TlsSocketPlugin
Custom implementation are activated using option `tlsSocketType`
Debugging
There is 2 options that can permit to debug :
- the option "enablePacketDebug"
- logging options
Using the Option "enablePacketDebug"
When any connection exception occurs, the stacktrace will a lot more verbose, containing the last 16 truncated exchanges with the server.
Example:
java.sql.SQLNonTransientConnectionException: (conn=7543) Could not send query: Software caused connection abort: recv failed at org.mariadb.jdbc.internal.util.exceptions.ExceptionMapper.get(ExceptionMapper.java:171) at org.mariadb.jdbc.internal.util.exceptions.ExceptionMapper.getException(ExceptionMapper.java:106) at org.mariadb.jdbc.MariaDbStatement.executeExceptionEpilogue(MariaDbStatement.java:235) at org.mariadb.jdbc.MariaDbStatement.executeInternal(MariaDbStatement.java:332) at org.mariadb.jdbc.MariaDbStatement.execute(MariaDbStatement.java:383) at org.mariadb.jdbc.ConnectionTest.testEnablePacketDebug(ConnectionTest.java:530) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:50) at org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12) at org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:47) at org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17) at org.junit.internal.runners.statements.RunBefores.evaluate(RunBefores.java:26) at org.junit.rules.TestWatcher$1.evaluate(TestWatcher.java:55) at org.junit.rules.RunRules.evaluate(RunRules.java:20) at org.junit.runners.ParentRunner.runLeaf(ParentRunner.java:325) at org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:78) at org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:57) at org.junit.runners.ParentRunner$3.run(ParentRunner.java:290) at org.junit.runners.ParentRunner$1.schedule(ParentRunner.java:71) at org.junit.runners.ParentRunner.runChildren(ParentRunner.java:288) at org.junit.runners.ParentRunner.access$000(ParentRunner.java:58) at org.junit.runners.ParentRunner$2.evaluate(ParentRunner.java:268) at org.junit.internal.runners.statements.RunBefores.evaluate(RunBefores.java:26) at org.junit.internal.runners.statements.RunAfters.evaluate(RunAfters.java:27) at org.junit.runners.ParentRunner.run(ParentRunner.java:363) at org.junit.runner.JUnitCore.run(JUnitCore.java:137) at com.intellij.junit4.JUnit4IdeaTestRunner.startRunnerWithArgs(JUnit4IdeaTestRunner.java:68) at com.intellij.rt.execution.junit.IdeaTestRunner$Repeater.startRunnerWithArgs(IdeaTestRunner.java:47) at com.intellij.rt.execution.junit.JUnitStarter.prepareStreamsAndStart(JUnitStarter.java:242) at com.intellij.rt.execution.junit.JUnitStarter.main(JUnitStarter.java:70) Caused by: java.sql.SQLException: Could not send query: Software caused connection abort: recv failed send at 2017-10-04T16:48:02.444Z 39 00 00 00 03 49 4E 53 45 52 54 20 49 4E 54 4F 9....INSERT INTO 20 74 65 73 74 45 6E 61 62 6C 65 50 61 63 6B 65 testEnablePacke 74 44 65 62 75 67 20 28 74 65 73 74 29 20 56 41 tDebug (test) VA 4C 55 45 53 20 28 27 68 65 6A 61 27 29 LUES ('heja') send at 2017-10-04T16:48:02.446Z 39 00 00 00 03 49 4E 53 45 52 54 20 49 4E 54 4F 9....INSERT INTO 20 74 65 73 74 45 6E 61 62 6C 65 50 61 63 6B 65 testEnablePacke 74 44 65 62 75 67 20 28 74 65 73 74 29 20 56 41 tDebug (test) VA 4C 55 45 53 20 28 27 6A 61 70 70 27 29 LUES ('japp') send at 2017-10-04T16:48:02.447Z 07 00 00 00 03 43 4F 4D 4D 49 54 .....COMMIT send at 2017-10-04T16:48:02.450Z 24 00 00 00 03 53 45 4C 45 43 54 20 2A 20 46 52 $....SELECT * FR 4F 4D 20 74 65 73 74 45 6E 61 62 6C 65 50 61 63 OM testEnablePac 6B 65 74 44 65 62 75 67 ketDebug send at 2017-10-04T16:48:02.452Z 3F 00 00 00 03 49 4E 53 45 52 54 20 49 4E 54 4F ?....INSERT INTO 20 74 65 73 74 45 6E 61 62 6C 65 50 61 63 6B 65 testEnablePacke 74 44 65 62 75 67 20 28 74 65 73 74 29 20 56 41 tDebug (test) VA 4C 55 45 53 20 28 27 72 6F 6C 6C 6D 65 62 61 63 LUES ('rollmebac 6B 27 29 k') read at 2017-10-04T16:48:02.453Z 07 00 00 01 .... 00 01 03 01 00 00 00 ....... send at 2017-10-04T16:48:02.454Z 09 00 00 00 03 52 4F 4C 4C 42 41 43 4B .....ROLLBACK send at 2017-10-04T16:48:02.457Z 2F 00 00 00 03 53 45 4C 45 43 54 20 2A 20 46 52 /....SELECT * FR 4F 4D 20 74 65 73 74 45 6E 61 62 6C 65 50 61 63 OM testEnablePac 6B 65 74 44 65 62 75 67 20 57 48 45 52 45 20 69 ketDebug WHERE i 64 3D 33 d=3 send at 2017-10-04T16:48:02.458Z 11 00 00 00 03 73 65 74 20 61 75 74 6F 63 6F 6D .....set autocom 6D 69 74 3D 31 mit=1 send at 2017-10-04T16:48:02.459Z 0F 00 00 00 03 53 45 4C 45 43 54 20 27 65 72 72 .....SELECT 'err 6F 72 27 or' Query is: SELECT 'error' at org.mariadb.jdbc.internal.util.LogQueryTool.exceptionWithQuery(LogQueryTool.java:119) at org.mariadb.jdbc.internal.protocol.AbstractQueryProtocol.executeQuery(AbstractQueryProtocol.java:162) at org.mariadb.jdbc.MariaDbStatement.executeInternal(MariaDbStatement.java:326) ... 29 more Caused by: java.net.SocketException: Software caused connection abort: recv failed at java.net.SocketInputStream.socketRead0(Native Method) at java.net.SocketInputStream.socketRead(SocketInputStream.java:116) at java.net.SocketInputStream.read(SocketInputStream.java:171) at java.net.SocketInputStream.read(SocketInputStream.java:141) at java.io.BufferedInputStream.fill(BufferedInputStream.java:246) at java.io.BufferedInputStream.read1(BufferedInputStream.java:286) at java.io.BufferedInputStream.read(BufferedInputStream.java:345) at org.mariadb.jdbc.internal.io.input.StandardPacketInputStream.getPacketArray(StandardPacketInputStream.java:238) at org.mariadb.jdbc.internal.io.input.StandardPacketInputStream.getPacket(StandardPacketInputStream.java:208) at org.mariadb.jdbc.internal.protocol.AbstractQueryProtocol.readPacket(AbstractQueryProtocol.java:1299) at org.mariadb.jdbc.internal.protocol.AbstractQueryProtocol.getResult(AbstractQueryProtocol.java:1280) at org.mariadb.jdbc.internal.protocol.AbstractQueryProtocol.executeQuery(AbstractQueryProtocol.java:159) ... 30 moreUsing Logging Options
The driver relies on the Slf4j framework. Slf4j is an abstraction for logging, which permits using the logger implementation of your choice.
Dependencies must be set using maven or be defined in the classpath.
Example using Logback implementation and maven :
<dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> <version>[1.4.0,1.7.25]</version> </dependency> <dependency> <groupId>ch.qos.logback</groupId> <artifactId>logback-classic</artifactId> <version>1.2.3</version> </dependency>Configurations are implementation dependant, but, most of them need to indicate the package name that have to be logged, and log level. Driver package is "org.mariadb.jdbc".
Be careful with "trace" level, purpose is to log all exchanges with server. This means huge amount of data. Bad configuration can lead to problems, like quickly filling the disk.
Log levels on slf4j are trace, debug, info, warn or error.
Example of configuring "trace" level on driver for logback: file logback.xml in src/main/resources/
<?xml version="1.0" encoding="UTF-8"?> <configuration> <appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"> <encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder"> <pattern>%d{yyyy-MM-dd HH:mm:ss} [%thread] %-5level %logger{36} - %msg%n</pattern> </encoder> </appender> <logger name="org.mariadb.jdbc" level="trace" additivity="false"> <appender-ref ref="STDOUT"/> </logger> <root level="error"> <appender-ref ref="STDOUT"/> </root> </configuration>The last step is to indicate driver to generate logging, setting options "profileSql" or "log" to true.
Exemple of generated logs :
2017-10-04 19:13:44 [main] TRACE o.m.j.i.i.o.StandardPacketOutputStream - send: conn=7548(M) 33 00 00 00 03 49 4E 53 45 52 54 20 49 4E 54 4F 3....INSERT INTO 20 44 72 69 76 65 72 74 33 30 20 28 74 65 73 74 Drivert30 (test 29 20 56 41 4C 55 45 53 20 28 27 72 6F 6C 6C 6D ) VALUES ('rollm 65 62 61 63 6B 27 29 eback') 2017-10-04 19:13:44 [main] TRACE o.m.j.i.i.i.StandardPacketInputStream - read: conn=7548(M) 07 00 00 01 .... 00 01 03 01 00 00 00 ....... 2017-10-04 19:13:44 [main] TRACE o.m.j.i.i.o.StandardPacketOutputStream - send: conn=7548(M) 09 00 00 00 03 52 4F 4C 4C 42 41 43 4B .....ROLLBACKContinuous Integration and Automated Tests
For MariaDB Connector/J's continuous integration and automated test results, please see MariaDB Connector/J's Travis CI.
MariaDB Connector/J's automated tests are run against the following MariaDB versions:
MariaDB Connector/J's automated tests are run with the following Java versions:
- Oracle JDK 6
- Oracle JDK 7
- Oracle JDK 8
- Oracle JDK 11
- OpenJDK 6
- OpenJDK 7
- OpenJDK 8
- OpenJDK 11
Reporting Bugs
If you find a bug, please report it via the CONJ project on MariaDB's Jira bug tracker.
Source Code
The source code is available at the mariadb-connector-j repository on GitHub.
License
GNU Lesser General Public License as published by the Free Software Foundation; either version 2.1 of the License, or (at your option) any later version.
For licensing questions, see the Licensing FAQ.
F.A.Q.
Error "Could not read resultset: unexpected end of stream, read 0 bytes from 4"
There is an issue communicating with the server.
Most of the time this will be caused by reading a query that has a large resultset; the server usually expects clients to read off the result set relatively quickly. The net_write_timeout server variable controls this behavior (defaults to 60s). If the client doesn't read the whole resultset in that amount of time, the server will discard the connection. If you don't expect results to be handled in this amount of time there is another possibility:
- if your server version >= MariaDB 10.1.2, you can use the query "SET STATEMENT net_write_timeout=10000 FOR XXX" with XXX being your "normal" query. This will indicate that specifically for this query, net_write_timeout will be set to a longer time (10000 in this example).
- for older servers, a specific query will have to temporarily set net_write_timeout ("SET STATEMENT net_write_timeout=..."), and set it back afterward.
- if your application usually uses a lot of long queries with fetch size, the connection can be set using the "sessionVariables=net_write_timeout=xxx" option.
How to Do a Lightweight Ping / Avoid Mass "select 1"
Connection.isValid() is a good approach. Connection.isValid() is doing a ping (ping in mysql protocol, not network ping). Connection pool using JDBC4 Validation are using automatically this Connection.isValid()
Comments
Источник: [https://torrent-igruha.org/3551-portal.html]4.3 Git on the Server - Generating Your SSH Public Key
Generating Your SSH Public Key
Many Git servers authenticate using SSH public keys. In order to provide a public key, each user in your system must generate one if they don’t already have one. This process is similar across all operating systems. First, you should check to make sure you don’t already have a key. By default, a user’s SSH keys are stored in that user’s directory. You can easily check to see if you have a key already by going to that directory and listing the contents:
You’re looking for a pair of files named something like or and a matching file with a extension. The file is your public key, and the other file is the corresponding private key. If you don’t have these files (or you don’t even have a directory), you can create them by running a program called , which is provided with the SSH package on Linux/macOS systems and comes with Git for Windows:
First it confirms where you want to save the key (), and then it asks twice for a passphrase, which you can leave empty if you don’t want to type a password when you use the key. However, if you do use a password, make sure to add the option; it saves the private key in a format that is more resistant to brute-force password cracking than is the default format. You can also use the tool to prevent having to enter the password each time.
Now, each user that does this has to send their public key to you or whoever is administrating the Git server (assuming you’re using an SSH server setup that requires public keys). All they have to do is copy the contents of the file and email it. The public keys look something like this:
What’s New in the JetBrains PyCharm v1.5.2 serial key or number?
Screen Shot

System Requirements for JetBrains PyCharm v1.5.2 serial key or number
- First, download the JetBrains PyCharm v1.5.2 serial key or number
-
You can download its setup from given links:

JetBrains PyCharm v1.5.2 serial key or number & Key Download

JetBrains PyCharm v1.5.2 serial key or number& Kali Software Crack
